Introduction
In this lesson, you will be learning a number of techniques to
- Clean and re-structure messy data.
- Convert columns to different data types.
- Tricks for manipulating NULLs.
This will give you a robust toolkit to get from raw data to clean data that’s useful for analysis.
LEFT AND RIGHT
Here we looked at three new functions:
- LEFT
- RIGHT
- LENGTH
LEFT pulls a specified number of characters for each row in a specified column starting at the beginning (or from the left). As you saw here, you can pull the first three digits of a phone number using LEFT(phone_number, 3).
RIGHT pulls a specified number of characters for each row in a specified column starting at the end (or from the right). As you saw here, you can pull the last eight digits of a phone number using RIGHT(phone_number, 8).
LENGTH provides the number of characters for each row of a specified column. Here, you saw that we could use this to get the length of each phone number as LENGTH(phone_number).
LEFT & RIGHT Quizzes
- In the accounts table, there is a column holding the website for each company. The last three digits specify what type of web address they are using. A list of extensions (and pricing) is provided here. Pull these extensions and provide how many of each website type exist in the accounts table.
WITH site_ext AS
(
SELECT website site, RIGHT(website, 4) AS ext
FROM accounts
)
SELECT ext, COUNT(*)
FROM site_ext
GROUP BY 1
- There is much debate about how much the name (or even the first letter of a company name) matters. Use the accounts table to pull the first letter of each company name to see the distribution of company names that begin with each letter (or number).
WITH first_let AS
(
SELECT name, LEFT(name, 1) AS first
FROM accounts
)
SELECT first, COUNT(*)
FROM first_let
GROUP BY 1
ORDER BY 2 DESC
- Use the accounts table and a CASE statement to create two groups: one group of company names that start with a number and a second group of those company names that start with a letter. What proportion of company names start with a letter?
My answer:
WITH first_let AS
(
SELECT name, LEFT(name, 1) AS first_letter
FROM accounts
ORDER BY 2
),
n_or_l AS
(
SELECT CASE WHEN first_letter NOT IN ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') THEN 'Letter'
ELSE 'Number'
END AS num_or_let
FROM first_let
)
SELECT num_or_let, COUNT(*)
FROM n_or_l
GROUP BY 1

Udacity’s
SELECT SUM(num) nums, SUM(letter) letters
FROM (
SELECT name,
CASE WHEN LEFT(UPPER(name), 1) IN ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') THEN 1
ELSE 0
END AS num,
CASE WHEN LEFT(UPPER(name), 1) IN ('0', '1', '2', '3', '4', '5', '6', '7', '8', '9') THEN 0
ELSE 1
END AS letter
FROM accounts
) t1;

There are 350 company names that start with a letter and 1 that starts with a number. This gives a ratio of 350/351 that are company names that start with a letter or 99.7%.
- Consider vowels as
a,e,i,o, andu. What proportion of company names start with a vowel, and what percent start with anything else?
WITH all_table AS
(
SELECT name,
CASE WHEN LEFT(UPPER(name), 1) IN ('A', 'E', 'I', 'O', 'U') THEN 1
ELSE 0
END AS vowels,
CASE WHEN LEFT(UPPER(name), 1) IN ('A', 'E', 'I', 'O', 'U') THEN 0
ELSE 1
END AS others
FROM accounts
)
SELECT SUM(vowels) vowels, SUM(others) others
FROM all_table
There are 80 company names that start with a vowel and 271 that start with other characters. Therefore 80/351 are vowels or 22.8%. Therefore, 77.2% of company names do not start with vowels.
POSITION, STRPOS, & SUBSTR
In this lesson, you learned about:
- POSITION
- STRPOS
- LOWER
- UPPER
POSITION takes a character and a column, and provides the index where that character is for each row. The index of the first position is 1 in SQL. If you come from another programming language, many begin indexing at 0. Here, you saw that you can pull the index of a comma as POSITION(‘,’ IN city_state).
STRPOS provides the same result as POSITION, but the syntax for achieving those results is a bit different as shown here: STRPOS(city_state, ‘,’).
Note, both POSITION and STRPOS are case sensitive, so looking for A is different than looking for a.
Therefore, if you want to pull an index regardless of the case of a letter, you might want to use LOWER or UPPER to make all of the characters lower or uppercase.
Quizzes POSITION & STRPOS
You will need to use what you have learned about LEFT & RIGHT, as well as what you know about POSITION or STRPOS to do the following quizzes.
- Use the
accountstable to create first and last name columns that hold the first and last names for theprimary_poc.
My Answer:
SELECT primary_poc,
LEFT(primary_poc,STRPOS(primary_poc, ' ')-1) AS first_name, RIGHT(primary_poc,-POSITION(' ' IN primary_poc )) AS last_name
FROM accounts
Udacity’s
SELECT LEFT(primary_poc, STRPOS(primary_poc, ' ') -1 ) first_name,
RIGHT(primary_poc, LENGTH(primary_poc) - STRPOS(primary_poc, ' ')) last_name
FROM accounts;
- Now see if you can do the same thing for every
repname in thesales_repstable. Again provide first and last name columns.
My Answer
SELECT name,
LEFT(name,position(' ' IN name)) AS first_name,
RIGHT(name,-position(' ' IN name)) AS last_name
FROM sales_reps
Udacity’s
SELECT LEFT(name, STRPOS(name, ' ') -1 ) first_name,
RIGHT(name, LENGTH(name) - STRPOS(name, ' ')) last_name
FROM sales_reps;
CONCAT
In this lesson you learned about:
- CONCAT
-
Piping
Each of these will allow you to combine columns together across rows. In this video, you saw how first and last names stored in separate columns could be combined together to create a full name: CONCAT(first_name, ' ', last_name) or with piping as first_name || ' ' || last_name.
Quizzes CONCAT
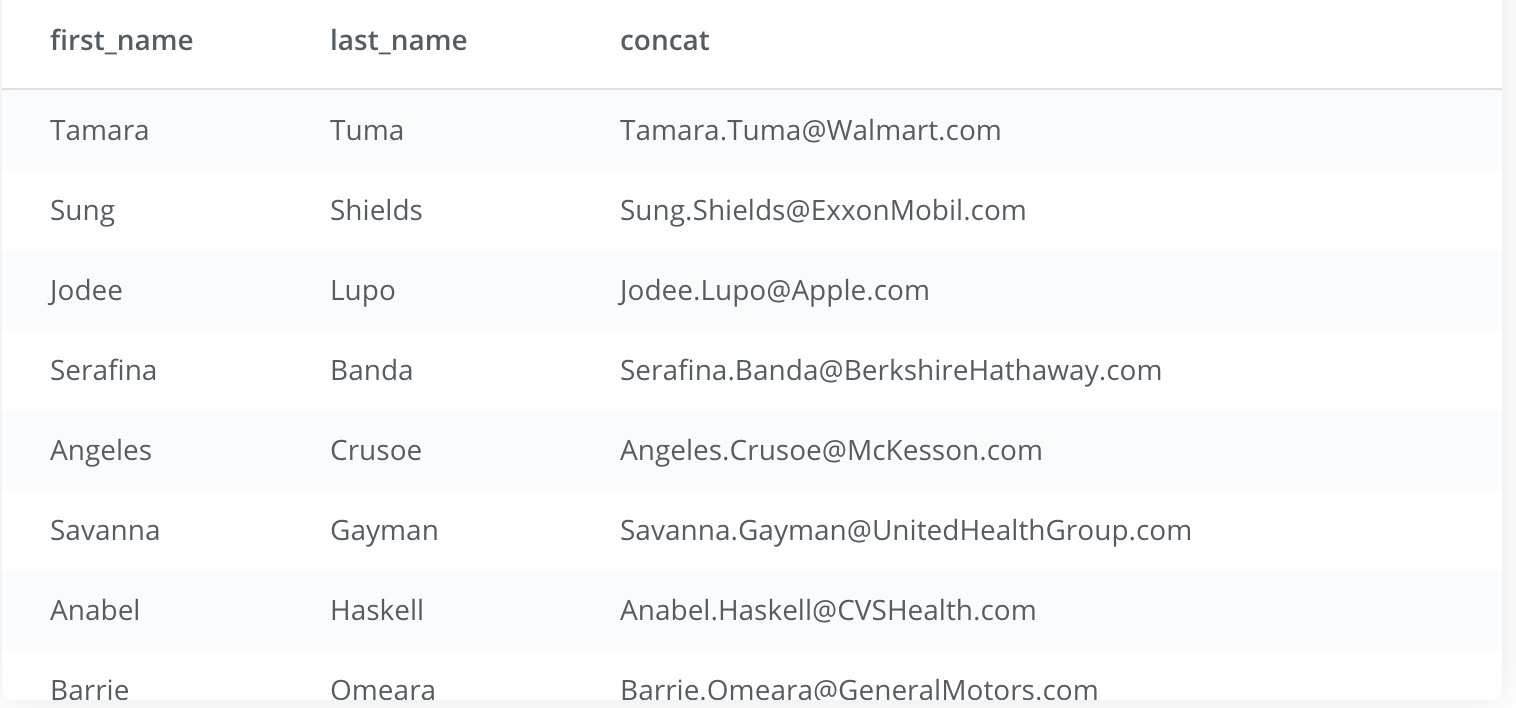
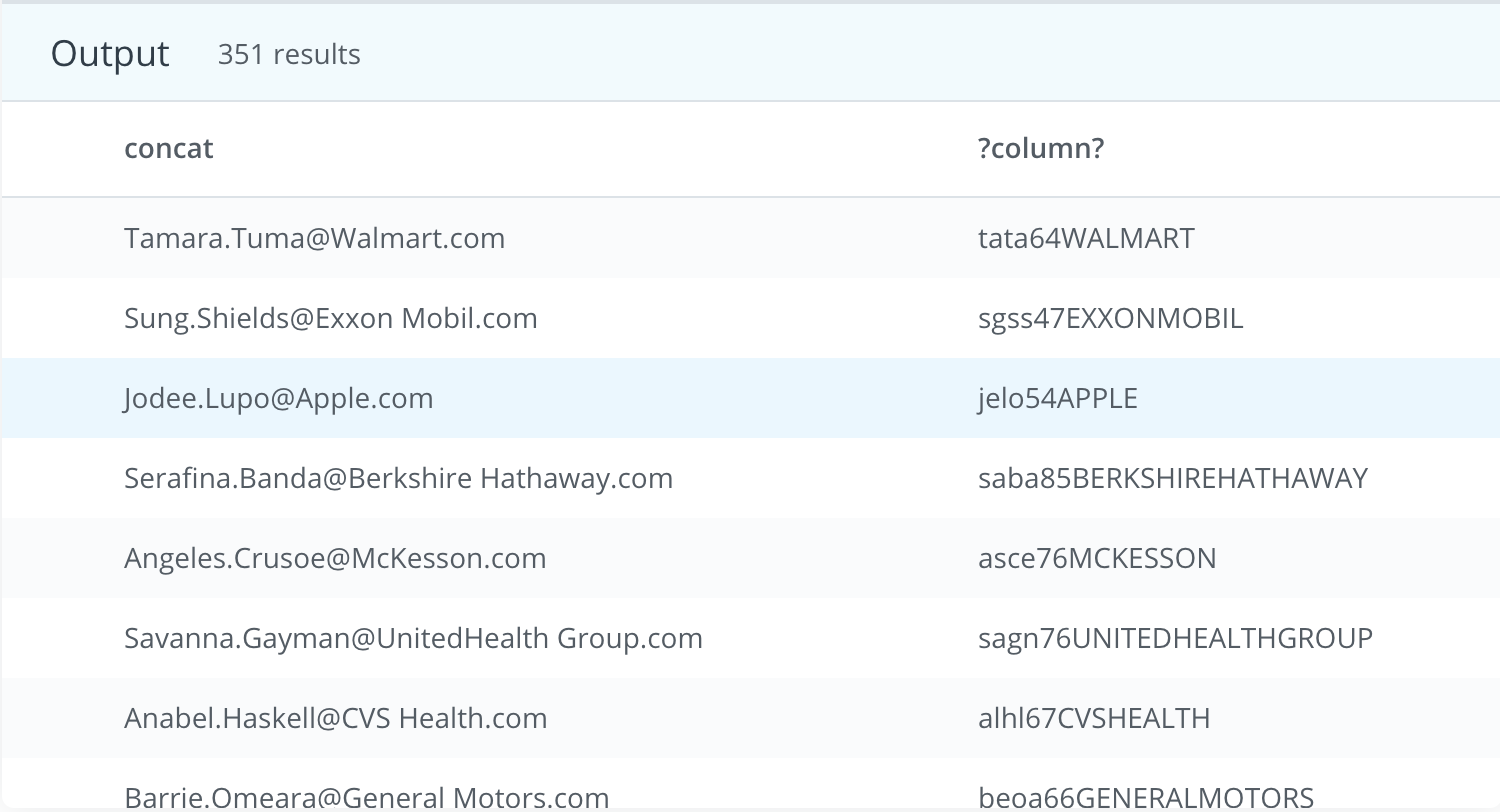
- Each company in the accounts table wants to create an email address for each primary_poc. The email address should be the first name of the primary_poc . last name primary_poc @ company name .com.
My Answer:
SELECT primary_poc, LEFT(LOWER(primary_poc),POSITION(' ' IN primary_poc)-1)||'.'||RIGHT(LOWER(primary_poc),-STRPOS(primary_poc,' '))||'@'|| REPLACE(LOWER(name), ' ', '')||'.'||'com' AS email
FROM accounts
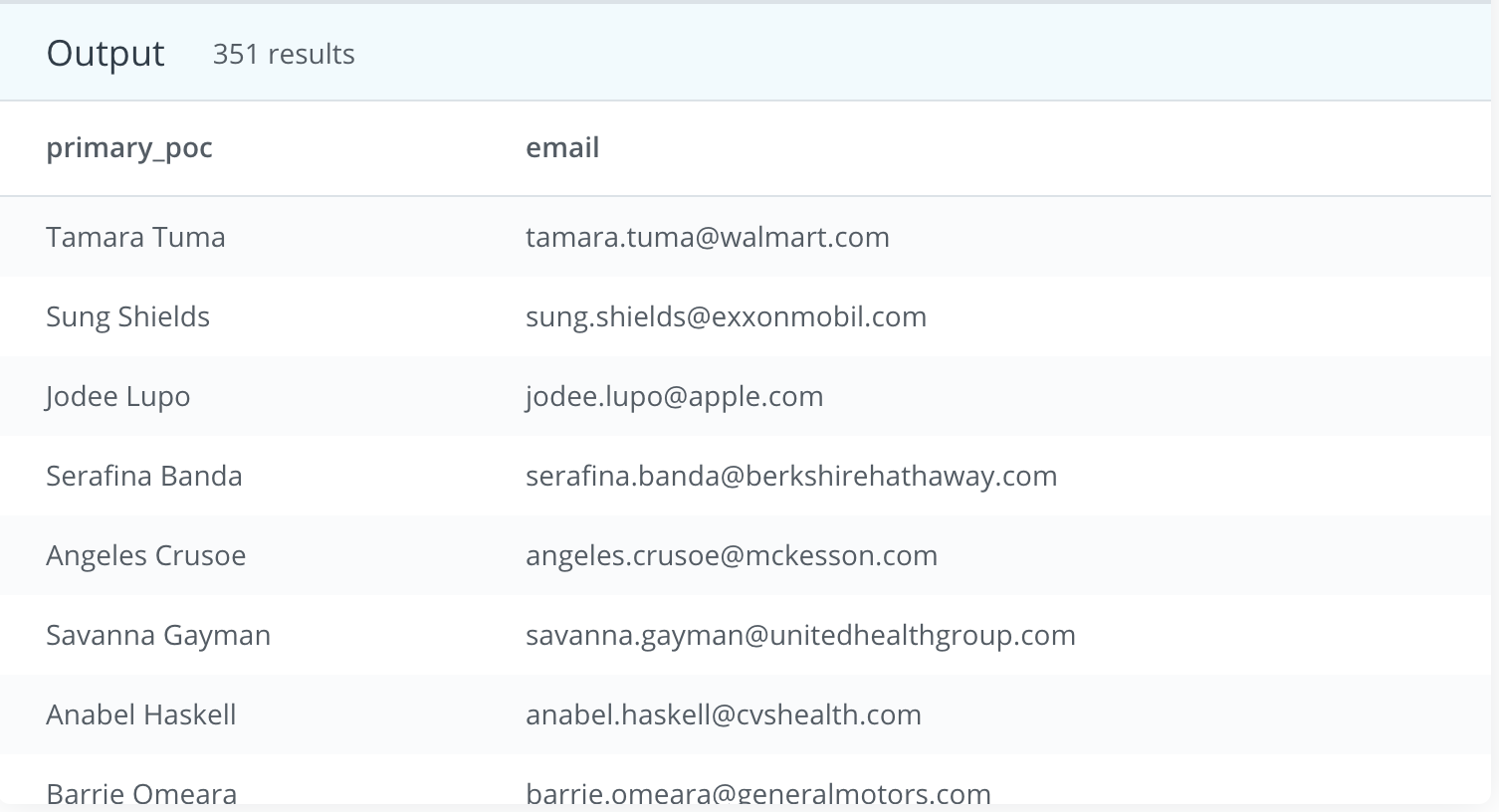
Udacity’s
WITH t1 AS (
SELECT LEFT(primary_poc, STRPOS(primary_poc, ' ') -1 ) first_name, RIGHT(primary_poc, LENGTH(primary_poc) - STRPOS(primary_poc, ' ')) last_name, name
FROM accounts)
SELECT first_name, last_name, CONCAT(first_name, '.', last_name, '@', name, '.com')
FROM t1;
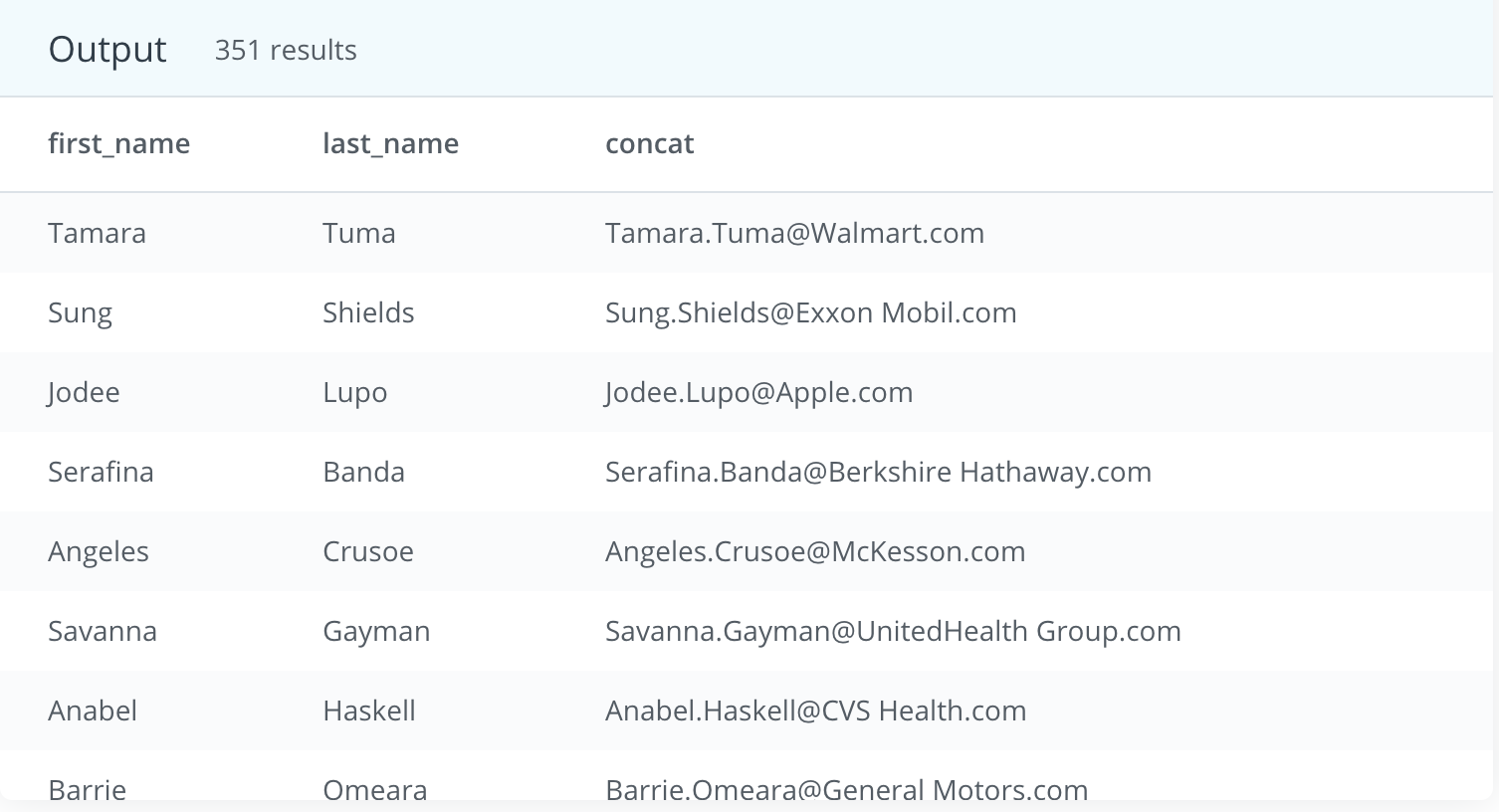
- You may have noticed that in the previous solution some of the company names include spaces, which will certainly not work in an email address. See if you can create an email address that will work by removing all of the spaces in the account name, but otherwise your solution should be just as in question 1. Some helpful documentation is here.
My Answer: Same as above
SELECT LEFT(LOWER(primary_poc),POSITION(' ' IN primary_poc)-1)||'.'||RIGHT(LOWER(primary_poc),-STRPOS(primary_poc,' '))||'@'|| REPLACE(LOWER(name), ' ', '')||'.'||'com' AS email
FROM accounts
Udacity’s
WITH t1 AS (
SELECT LEFT(primary_poc, STRPOS(primary_poc, ' ') -1 ) first_name, RIGHT(primary_poc, LENGTH(primary_poc) - STRPOS(primary_poc, ' ')) last_name, name
FROM accounts)
SELECT first_name, last_name, CONCAT(first_name, '.', last_name, '@', REPLACE(name, ' ', ''), '.com')
FROM t1;
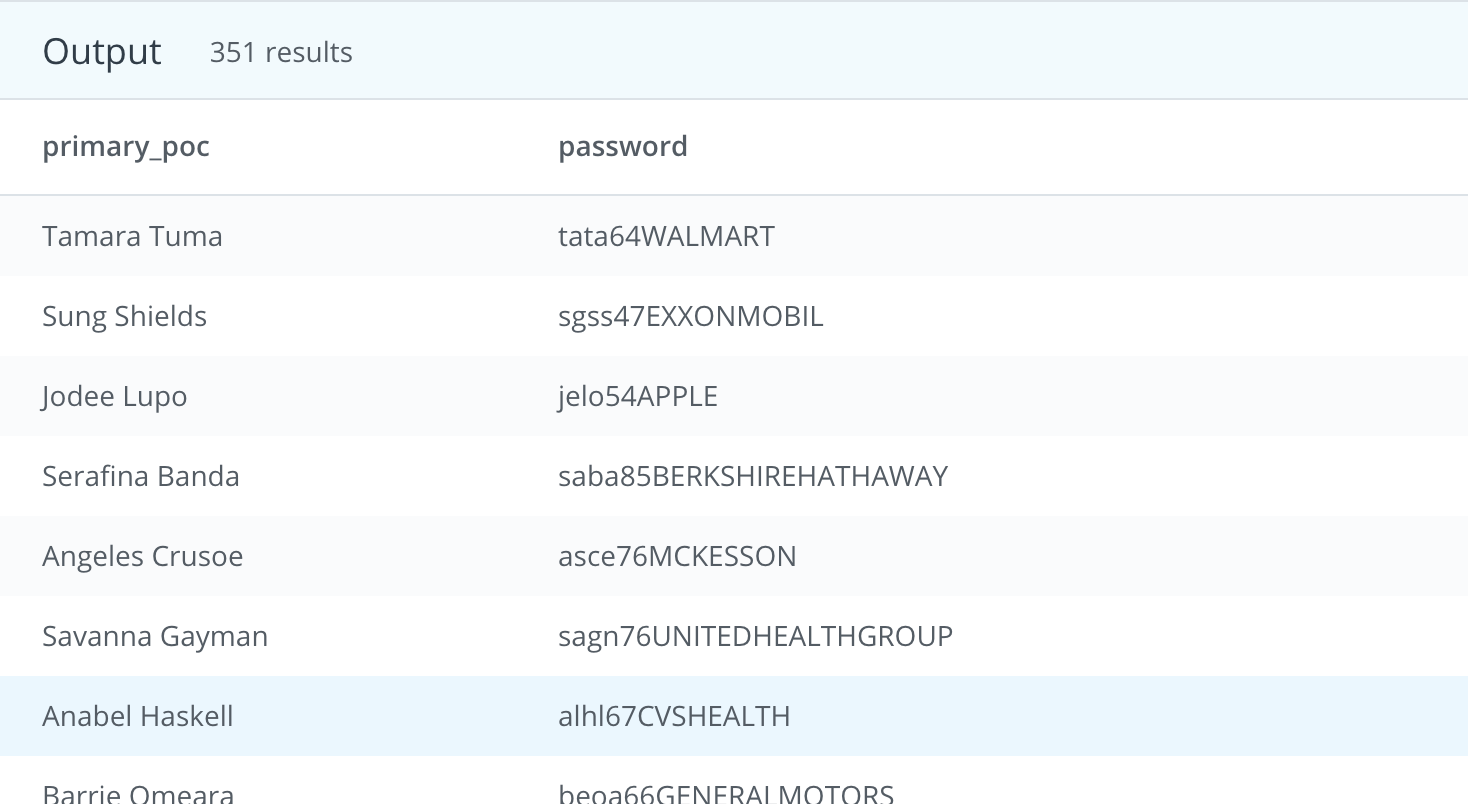
- We would also like to create an initial password, which they will change after their first log in. The first password will be the first letter of the primary_poc’s first name (lowercase), then the last letter of their first name (lowercase), the first letter of their last name (lowercase), the last letter of their last name (lowercase), the number of letters in their first name, the number of letters in their last name, and then the name of the company they are working with, all capitalized with no spaces.
My Answer:
WITH password_table AS
(
SELECT primary_poc,
LEFT(LOWER(primary_poc), 1) AS first_let_firstname,
RIGHT(LEFT(primary_poc, POSITION(' ' IN primary_poc)-1),1)
AS last_let_firstname,
LEFT(RIGHT(LOWER(primary_poc), -POSITION(' ' IN primary_poc)),1)
AS first_let_lastname,
RIGHT(RIGHT(LOWER(primary_poc),-POSITION(' ' IN primary_poc)-1),1)
AS last_let_lastname,
LENGTH(LEFT(primary_poc, POSITION(' ' in primary_poc)-1))
AS length_first_name,
LENGTH(RIGHT(primary_poc, - STRPOS(primary_poc, ' ')))
AS length_last_name,
REPLACE(UPPER(name), ' ', '') AS company
FROM accounts
)
SELECT
primary_poc,
CONCAT (
first_let_firstname,
last_let_firstname,
first_let_lastname,
last_let_lastname,
length_first_name,
length_last_name,
company
) as password
FROM password_table
Udacity’s
WITH t1 AS (
SELECT LEFT(primary_poc, STRPOS(primary_poc, ' ') -1 ) first_name, RIGHT(primary_poc, LENGTH(primary_poc) - STRPOS(primary_poc, ' ')) last_name, name
FROM accounts)
SELECT first_name, last_name, CONCAT(first_name, '.', last_name, '@', name, '.com'), LEFT(LOWER(first_name), 1) || RIGHT(LOWER(first_name), 1) || LEFT(LOWER(last_name), 1) || RIGHT(LOWER(last_name), 1) || LENGTH(first_name) || LENGTH(last_name) || REPLACE(UPPER(name), ' ', '')
FROM t1;
CAST
In this video, you saw additional functionality for working with dates including:
- TO_DATE
- CAST
- Casting with
::
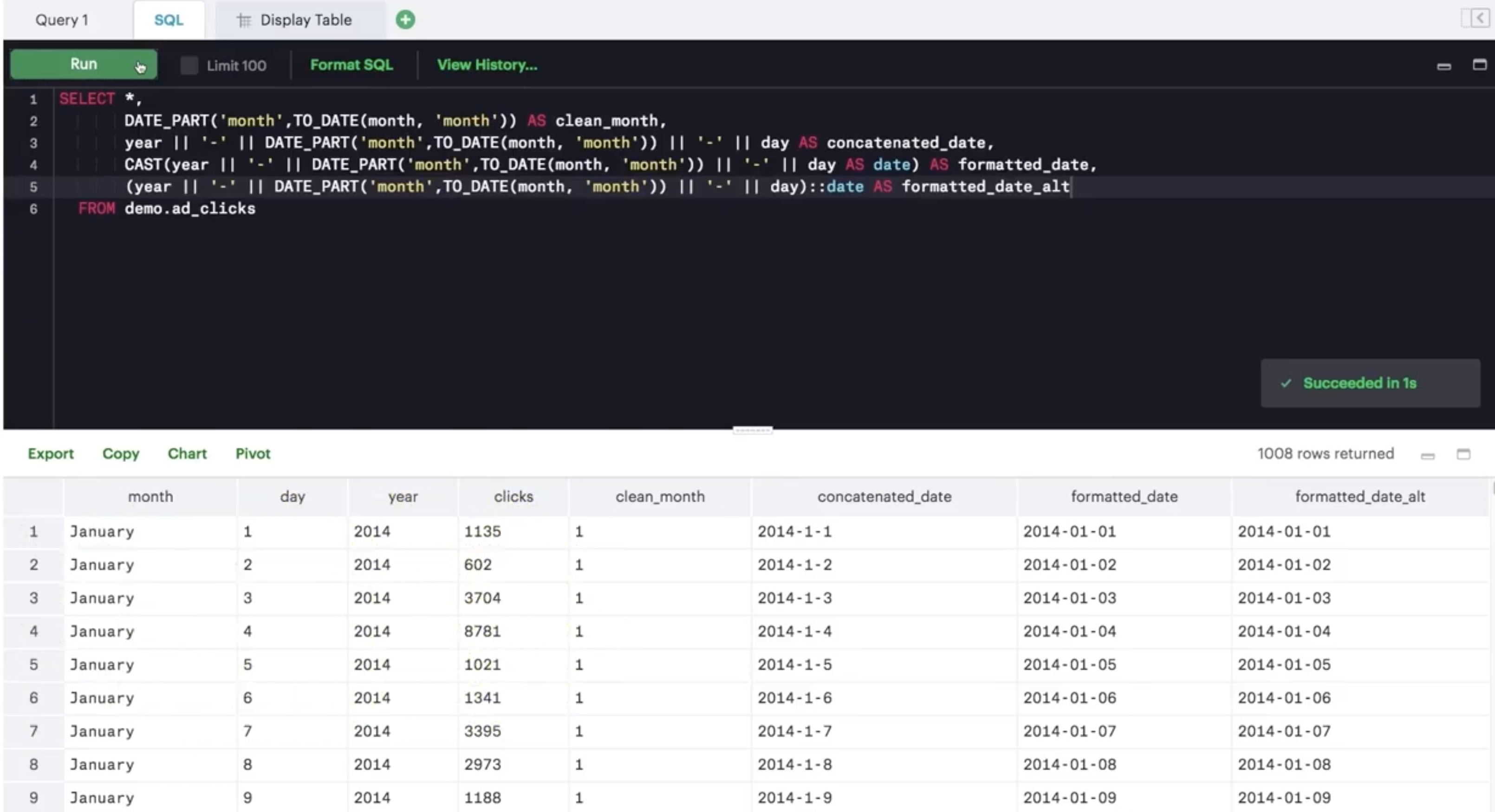
DATE_PART(‘month’, TO_DATE(month, ‘month’)) here changed a month name into the number associated with that particular month.
Then you can change a string to a date using CAST. CAST is actually useful to change lots of column types. Commonly you might be doing as you saw here, where you change a string to a date using CAST(date_column AS DATE). However, you might want to make other changes to your columns in terms of their data types. You can see other examples here.
In this example, you also saw that instead of CAST(date_column AS DATE), you can use date_column::DATE.
Expert Tip Most of the functions presented in this lesson are specific to strings. They won’t work with dates, integers or floating-point numbers. However, using any of these functions will automatically change the data to the appropriate type.
LEFT, RIGHT, and TRIM are all used to select only certain elements of strings, but using them to select elements of a number or date will treat them as strings for the purpose of the function. Though we didn’t cover TRIM in this lesson explicitly, it can be used to remove characters from the beginning and end of a string. This can remove unwanted spaces at the beginning or end of a row that often happen with data being moved from Excel or other storage systems.
There are a number of variations of these functions, as well as several other string functions not covered here. Different databases use subtle variations on these functions, so be sure to look up the appropriate database’s syntax if you’re connected to a private database.The Postgres literature contains a lot of the related functions.
Cast Quiz

WITH date_table AS
(
SELECT date,
SUBSTR(date, 1, STRPOS(date, '/') -1) AS month,
SUBSTR(date, 4, STRPOS(date, '/') -1) AS day,
RIGHT(TRIM(LEFT(date, POSITION(' ' in date))),4) AS year
FROM sf_crime_data
)
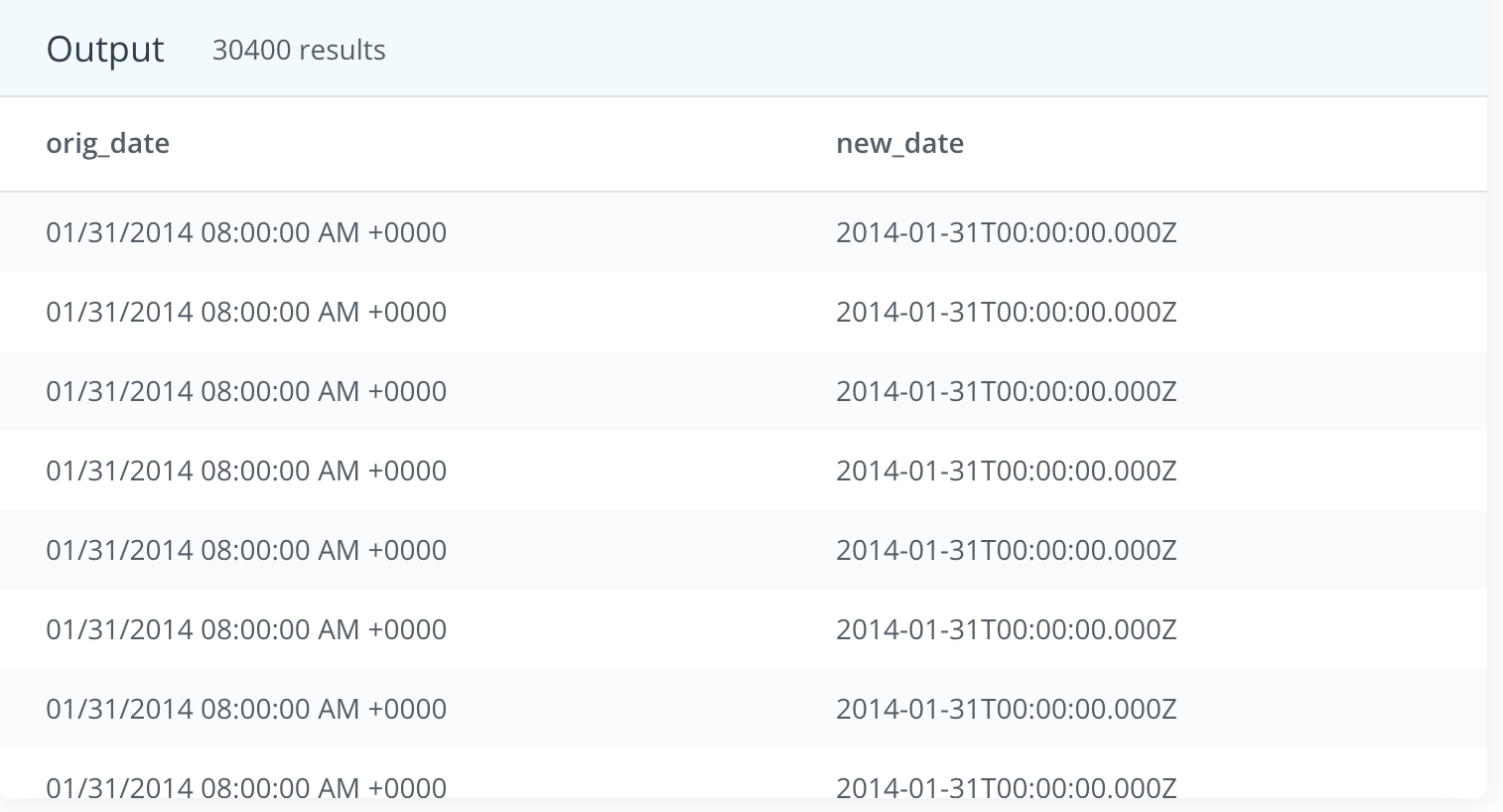
SELECT
date AS orig_date, CAST(CONCAT(year, '-', month, '-', day) AS date) AS new_date
FROM date_table
COALESCE
In this video, you learned about how to use COALESCE to work with NULL values. Unfortunately, our dataset does not have the NULL values that were fabricated in this dataset, so you will work through a different example in the next concept to get used to the COALESCE function.
In general, COALESCE returns the first non-NULL value passed for each row. Hence why the video used no_poc if the value in the row was NULL.
###COALESCE Quizzes In this quiz, we will walk through the previous example using the following task list. We will use the COALESCE function to complete the orders record for the row in the table output.
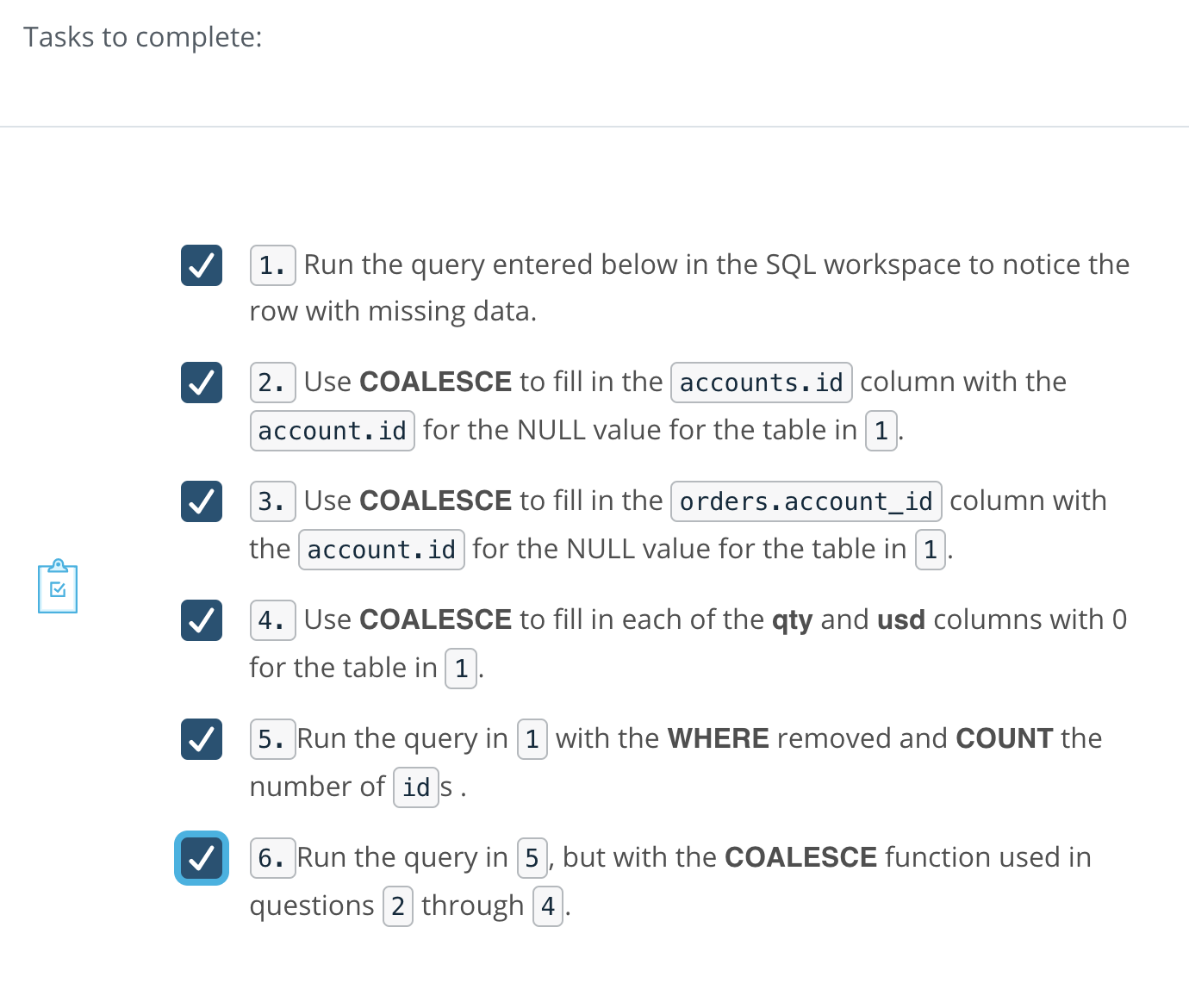
SELECT *
FROM accounts a
LEFT JOIN orders o
ON a.id = o.account_id
WHERE o.total IS NULL;
SELECT COALESCE(a.id, a.id) filled_id, a.name, a.website, a.lat, a.long, a.primary_poc, a.sales_rep_id, o.*
FROM accounts a
LEFT JOIN orders o
ON a.id = o.account_id
WHERE o.total IS NULL;
SELECT COALESCE(a.id, a.id) filled_id, a.name, a.website, a.lat, a.long, a.primary_poc, a.sales_rep_id, COALESCE(o.account_id, a.id) account_id, o.occurred_at, o.standard_qty, o.gloss_qty, o.poster_qty, o.total, o.standard_amt_usd, o.gloss_amt_usd, o.poster_amt_usd, o.total_amt_usd
FROM accounts a
LEFT JOIN orders o
ON a.id = o.account_id
WHERE o.total IS NULL;
SELECT COALESCE(a.id, a.id) filled_id, a.name, a.website, a.lat, a.long, a.primary_poc, a.sales_rep_id, COALESCE(o.account_id, a.id) account_id, o.occurred_at, COALESCE(o.standard_qty, 0) standard_qty, COALESCE(o.gloss_qty,0) gloss_qty, COALESCE(o.poster_qty,0) poster_qty, COALESCE(o.total,0) total, COALESCE(o.standard_amt_usd,0) standard_amt_usd, COALESCE(o.gloss_amt_usd,0) gloss_amt_usd, COALESCE(o.poster_amt_usd,0) poster_amt_usd, COALESCE(o.total_amt_usd,0) total_amt_usd
FROM accounts a
LEFT JOIN orders o
ON a.id = o.account_id
WHERE o.total IS NULL;
SELECT COUNT(\*)
FROM accounts a
LEFT JOIN orders o
ON a.id = o.account_id;
SELECT COALESCE(a.id, a.id) filled_id, a.name, a.website, a.lat, a.long, a.primary_poc, a.sales_rep_id, COALESCE(o.account_id, a.id) account_id, o.occurred_at, COALESCE(o.standard_qty, 0) standard_qty, COALESCE(o.gloss_qty,0) gloss_qty, COALESCE(o.poster_qty,0) poster_qty, COALESCE(o.total,0) total, COALESCE(o.standard_amt_usd,0) standard_amt_usd, COALESCE(o.gloss_amt_usd,0) gloss_amt_usd, COALESCE(o.poster_amt_usd,0) poster_amt_usd, COALESCE(o.total_amt_usd,0) total_amt_usd
FROM accounts a
LEFT JOIN orders o
ON a.id = o.account_id;
Video + Text: Recap
You now have a number of tools to assist in cleaning messy data in SQL. Manually cleaning data is tedious, but you now can clean data at scale using your new skills.
For a reminder on any of the data cleaning functionality, the concepts in this lesson are labeled according to the functions you learned. If you felt uncomfortable with any of these functions at first, that is normal - these take some getting used to. Don’t be afraid to take a second pass through the material to sharpen your skills!
Memorizing all of this functionality isn’t necessary, but you do need to be able to follow documentation, and learn from what you have done in solving previous problems to solve new problems.
There are a few other functions that work similarly. You can read more about those here. You can also get a walk through of many of the functions you have seen throughout this lesson here.
Nice job on this section!