Lesson 1: Descriptive Statistics
Introduction to Data Types
Quantitative and Categorical
Quantitative data takes on numeric values that allow us to perform mathematical operations (like the number of dogs).
We can think of quantitative data as being either continuous or discrete.
Continuous data can be split into smaller and smaller units, and still a smaller unit exists. An example of this is the age of the dog - we can measure the units of the age in years, months, days, hours, seconds, but there are still smaller units that could be associated with the age.
Discrete data only takes on countable values. The number of dogs we interact with is an example of a discrete data type.
Categorical are used to label a group or set of items (like dog breeds - Collies, Labs, Poodles, etc.).
Categorical Ordinal vs. Categorical Nominal ![]() We can divide categorical data further into two types: Ordinal and Nominal.
We can divide categorical data further into two types: Ordinal and Nominal.
Categorical Ordinal data take on a ranked ordering (like a ranked interaction on a scale from Very Poor to Very Good with the dogs).
Categorical Nominal data do not have an order or ranking (like the breeds of the dog).
Recap
| DATA TYPES | ||
|---|---|---|
| Quantitative: | Continuous | Discrete |
| Height, Age, Income | Pages in a Book, Trees in Yard, Dogs at a Coffee Shop | |
| Categorical: | Ordinal | Nominal |
| Letter Grade, Survey Rating | Gender, Marital Status, Breakfast Items |
Quantitative vs. Categorical
Some of these can be a bit tricky - notice even though zip codes are a number, they aren’t really a quantitative variable. If we add two zip codes together, we do not obtain any useful information from this new value. Therefore, this is a categorical variable.
Height, Age, the Number of Pages in a Book and Annual Income all take on values that we can add, subtract and perform other operations with to gain useful insight. Hence, these are quantitative.
Gender, Letter Grade, Breakfast Type, Marital Status, and Zip Code can be thought of as labels for a group of items or individuals. Hence, these are categorical.
Continuous vs. Discrete
To consider if we have continuous or discrete data, we should see if we can split our data into smaller and smaller units. Consider time - we could measure an event in years, months, days, hours, minutes, or seconds, and even at seconds we know there are smaller units we could measure time in. Therefore, we know this data type is continuous. Height, age, and income are all examples of continuous data. Alternatively, the number of pages in a book, dogs I count outside a coffee shop, or trees in a yard are discrete data. We would not want to split our dogs in half.
Continuous data types are those that can take on decimal values, where discrete data types are those that are countable.
Ordinal vs. Nominal
In looking at categorical variables, we found Gender, Marital Status, Zip Code and your Breakfast items are nominal variables where there is no order ranking associated with this type of data. Whether you ate cereal, toast, eggs, or only coffee for breakfast; there is no rank ordering associated with your breakfast.
Alternatively, the Letter Grade or Survey Ratings have a rank ordering associated with it, as ordinal data. If you receive an A, this is higher than an A-. An A- is ranked higher than a B+, and so on… Ordinal variables frequently occur on rating scales from very poor to very good. In many cases we turn these ordinal variables into numbers, as we can more easily analyze them, but more on this later!
Final Words
In this section, we looked at the different data types we might work with in the world around us. When we work with data in the real world, it might not be very clean - sometimes there are typos or missing values. When this is the case, simply having some expertise regarding the data and knowing the data type can assist in our ability to ‘clean’ this data. Understanding data types can also assist in our ability to build visuals to best explain the data. But more on this very soon!
Introduction to Summary Statistics
Analyzing Quantitative Data
Four Aspects for Quantitative Data
There are four main aspects to analyzing Quantitative data.
- Measures of Center
- Measures of Spread
- The Shape of the data.
- Outliers
Analyzing Categorical Data
Though not discussed in the video, analyzing categorical data has fewer parts to consider. Categorical data is analyzed usually by looking at the counts or proportion of individuals that fall into each group. For example if we were looking at the breeds of the dogs, we would care about how many dogs are of each breed, or what proportion of dogs are of each breed type.
Measures of Center
There are three measures of center:
-
The Mean
 In this video, we focused on the calculation of the mean. The mean is often called the average or the expected value in mathematics. We calculate the mean by adding all of our values together, and dividing by the number of values in our dataset.
In this video, we focused on the calculation of the mean. The mean is often called the average or the expected value in mathematics. We calculate the mean by adding all of our values together, and dividing by the number of values in our dataset. -
The Median
The median splits our data so that 50% of our values are lower and 50% are higher. We found in this video that how we calculate the median depends on if we have an even number of observations or an odd number of observations.
Median for Odd Values
If we have an odd number of observations, the median is simply the number in the direct middle. For example, if we have 7 observations, the median is the fourth value when our numbers are ordered from smallest to largest. If we have 9 observations, the median is the fifth value.
Median for Even Values
If we have an even number of observations, the median is the average of the two values in the middle. For example, if we have 8 observations, we average the fourth and fifth values together when our numbers are ordered from smallest to largest.
In order to compute the median we MUST sort our values first.
Whether we use the mean or median to describe a dataset is largely dependent on the shape of our dataset and if there are any outliers. We will talk about this in just a bit!
-
The Mode
The mode is the most frequently observed value in our dataset.
There might be multiple modes for a particular dataset, or no mode at all.
No Mode
If all observations in our dataset are observed with the same frequency, there is no mode. If we have the dataset:
1, 1, 2, 2, 3, 3, 4, 4
There is no mode, because all observations occur the same number of times.
Many Modes
If two (or more) numbers share the maximum value, then there is more than one mode. If we have the dataset:
1, 2, 3, 3, 3, 4, 5, 6, 6, 6, 7, 8, 9
There are two modes 3 and 6, because these values share the maximum frequencies at 3 times, while all other values only appear once.
What is Notation?
Notation
Notation is a common language used to communicate mathematical ideas. Think of notation as a universal language used by academic and industry professionals to convey mathematical ideas.
You likely already know some notation. Plus, minus, multiply, division, and equal signs all have mathematical symbols that you are likely familiar with. Each of these symbols replaces an idea for how numbers interact with one another. In the coming concepts, you will be introduced to some additional ideas related to notation. Though you will not need to use notation to complete the project, it does have the following properties:
-
Understanding how to correctly use notation makes you seem really smart. Knowing how to read and write in notation is like learning a new language. A language that is used to convey ideas associated with mathematics.
-
It allows you to read documentation, and implement an idea to your own problem. Notation is used to convey how problems are solved all the time. One really popular mathematical algorithm that is used to solve some of the world’s most difficult problems is known as Gradient Boosting. The way that it solves problems is explained here: https://en.wikipedia.org/wiki/Gradient_boosting. If you really want to understand how this algorithm works, you need to be able to read and understand notation.
-
It makes ideas that are hard to say in words easier to convey. Sometimes we just don’t have the right words to say. For those situations, I prefer to use notation to convey the message. Similar to the way an emoji or meme might convey a feeling better than words, notation can convey an idea better than words. Usually those ideas are related to mathematics, but I am not here to stifle your creativity.
Random Variales
Example to Introduce Notation
There is a lot going on in this video - here is a recap of the big ideas.
Rows and Columns
If you aren’t familiar with spreadsheets, this will be covered in detail in future lessons. Spreadsheets are a common way to hold data. They are composed of rows and columns. Rows run horizontally, while columns run vertically. Each column in a spreadsheet commonly holds a specific variable, while each row is commonly called an instance or individual.
The example used in the video is shown below.
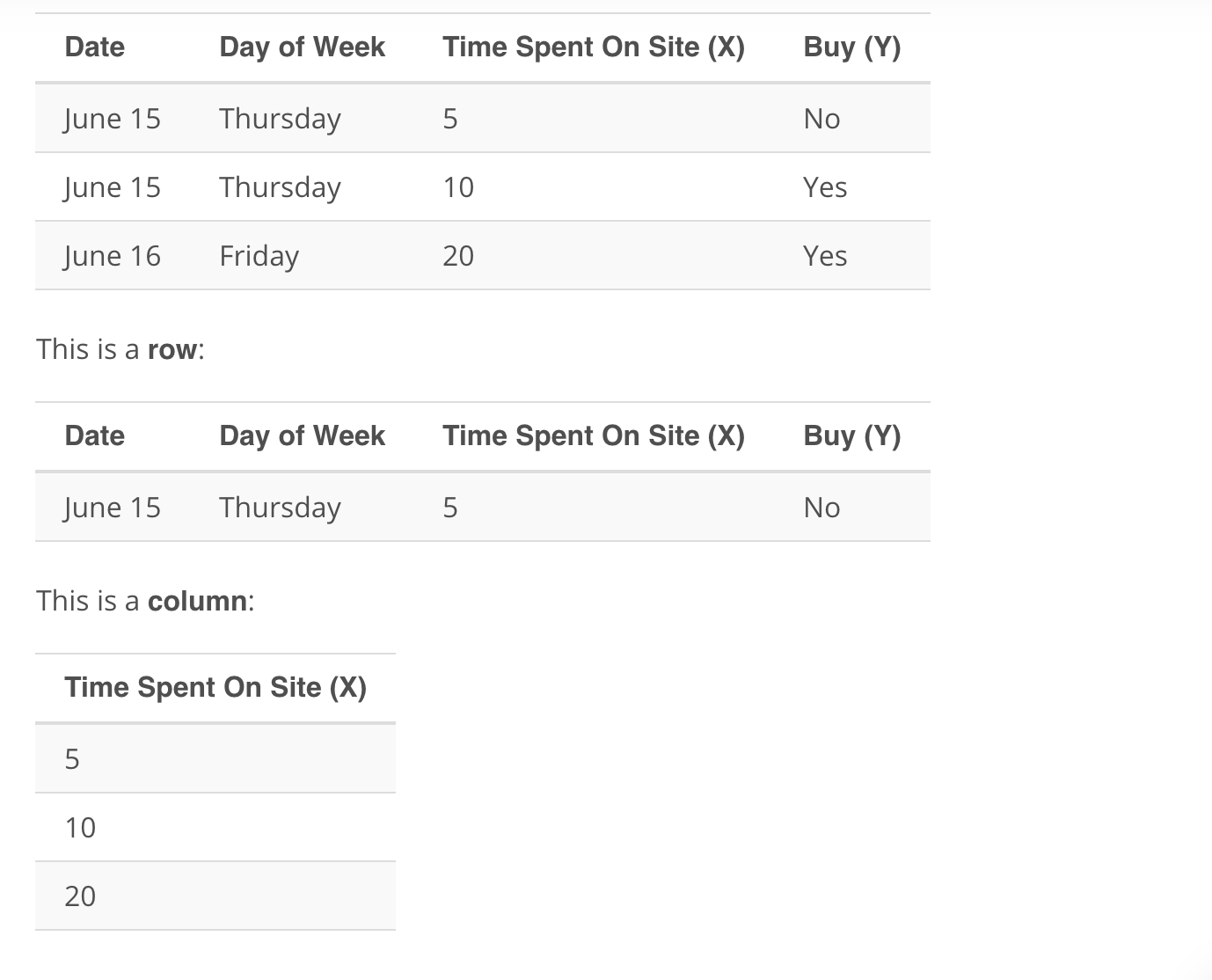
Before Collecting Data
Before collecting data, we usually start with a question, or many questions, that we would like to answer. The purpose of data is to help us in answering these questions.
Random Variables
A random variable is a placeholder for the possible values of some process (mostly… the term ‘some process’ is a bit ambiguous). As was stated before, notation is useful in that it helps us take complex ideas and simplify (often to a single letter or single symbol). We see random variables represented by capital letters (X, Y, or Z are common ways to represent a random variable).
We might have the random variable X, which is a holder for the possible values of the amount of time someone spends on our site. Or the random variable Y, which is a holder for the possible values of whether or not an individual purchases a product.
X is ‘a holder’ of the values that could possibly occur for the amount of time spent on our website. Any number from 0 to infinity really.
Capital vs. Lower
Capital vs. Lower Case Letters
Random variables are represented by capital letters. Once we observe an outcome of these random variables, we notate it as a lower case of the same letter.
Example 1
For example, the amount of time someone spends on our site is a random variable (we are not sure what the outcome will be for any particular visitor), and we would notate this with X. Then when the first person visits the website, if they spend 5 minutes, we have now observed this outcome of our random variable. We would notate any outcome as a lowercase letter with a subscript associated with the order that we observed the outcome.
If 5 individuals visit our website, the first spends 10 minutes, the second spends 20 minutes, the third spends 45 mins, the fourth spends 12 minutes, and the fifth spends 8 minutes; we can notate this problem in the following way:
X is the amount of time an individual spends on the website.
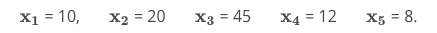
The capital X is associated with this idea of a random variable, while the observations of the random variable take on lowercase x values.
Example 2
Taking this one step further, we could ask:
What is the probability someone spends more than 20 minutes in our website?
In notation, we would write:
P(X > 20)?
Here P stands for probability, while the parentheses encompass the statement for which we would like to find the probability. Since X represents the amount of time spent on the website, this notation represents the probability the amount of time on the website is greater than 20.
We could find this in the above example by noticing that only one of the 5 observations exceeds 20. So, we would say there is a 1 (the 45) in 5 or 20% chance that an individual spends more than 20 minutes on our website (based on this dataset).
Example 3
If we asked: What is the probability of an individual spending 20 or more minutes on our website? We could notate this as:
P(X \geq≥ 20)?
We could then find this by noticing there are two out of the five individuals that spent 20 or more minutes on the website. So this probability is 2 out of 5 or 40%.
Notation for Calculating the Mean
We know that the mean is calculated as the sum of all our values divided by the number of values in our dataset.
In our current notation, adding all of our values together can be extremely tedious. If we want to add 3 values of some random variable together, we would use the notation:
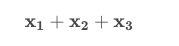
If we want to add 6 values together, we would use the notation:
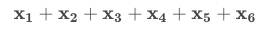
To extend this to add one hundred, one thousand, or one million values would be ridiculous! How can we make this easier to communicate?!
Aggregations
An aggregation is a way to turn multiple numbers into fewer numbers (commonly one number).
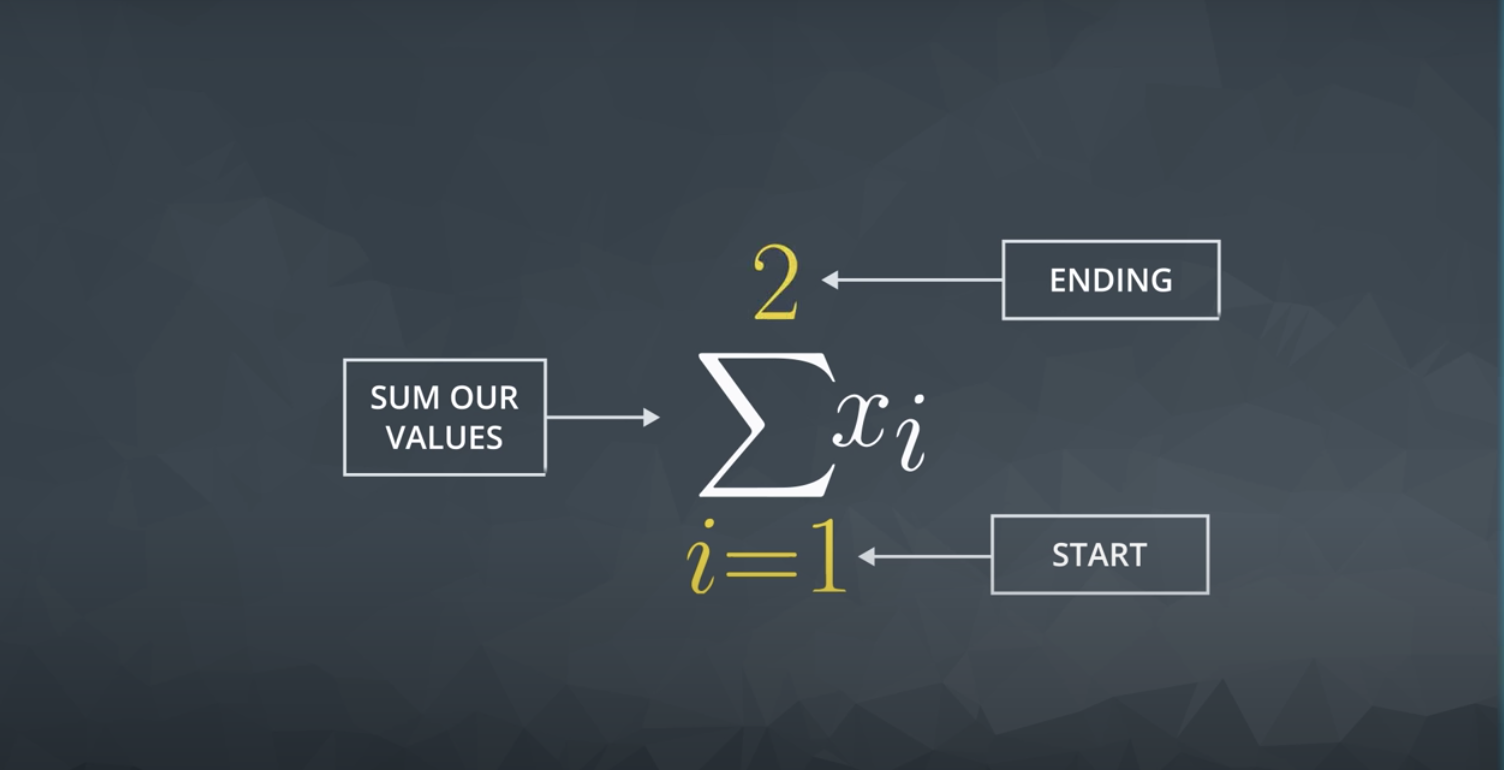
Summation ![]() is a common aggregation. The notation used to sum our values is a greek symbol called sigma Σ.
is a common aggregation. The notation used to sum our values is a greek symbol called sigma Σ.
Example 1
Imagine we are looking at the amount of time individuals spend on our website. We collect data from nine individuals:
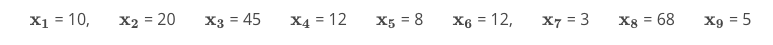
If we want to sum the first three values together in our previous notation, we write:
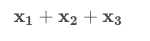
In our new notation, we can write:
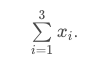 Notice, our notation starts at the first observation (i=1i=1) and ends at 3 (the number at the top of our summation).
Notice, our notation starts at the first observation (i=1i=1) and ends at 3 (the number at the top of our summation).
So all of the following are equal to one another:

Example 2
Now, imagine we want to sum the last three values together.
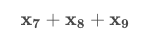
In our new notation, we can write:
In our new notation, we can write:
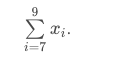
Notice, our notation starts at the seventh observation (i=7i=7) and ends at 9 (the number at the top of our summation).
Other Aggregations
The Σ is used for aggregating using summation, but we might choose to aggregate in other ways. Summing is one of the most common ways to need to aggregate. However, we might need to aggregate in alternative ways. If we wanted to multiply all of our values together we would use a Π , capital Greek letter pi. The way we aggregate continuous values is with something known as integration (a common technique in calculus), which uses the following symbol ∫ which is just a long s. We will not be using integrals or products for quizzes in this class, but you may see them in the future!
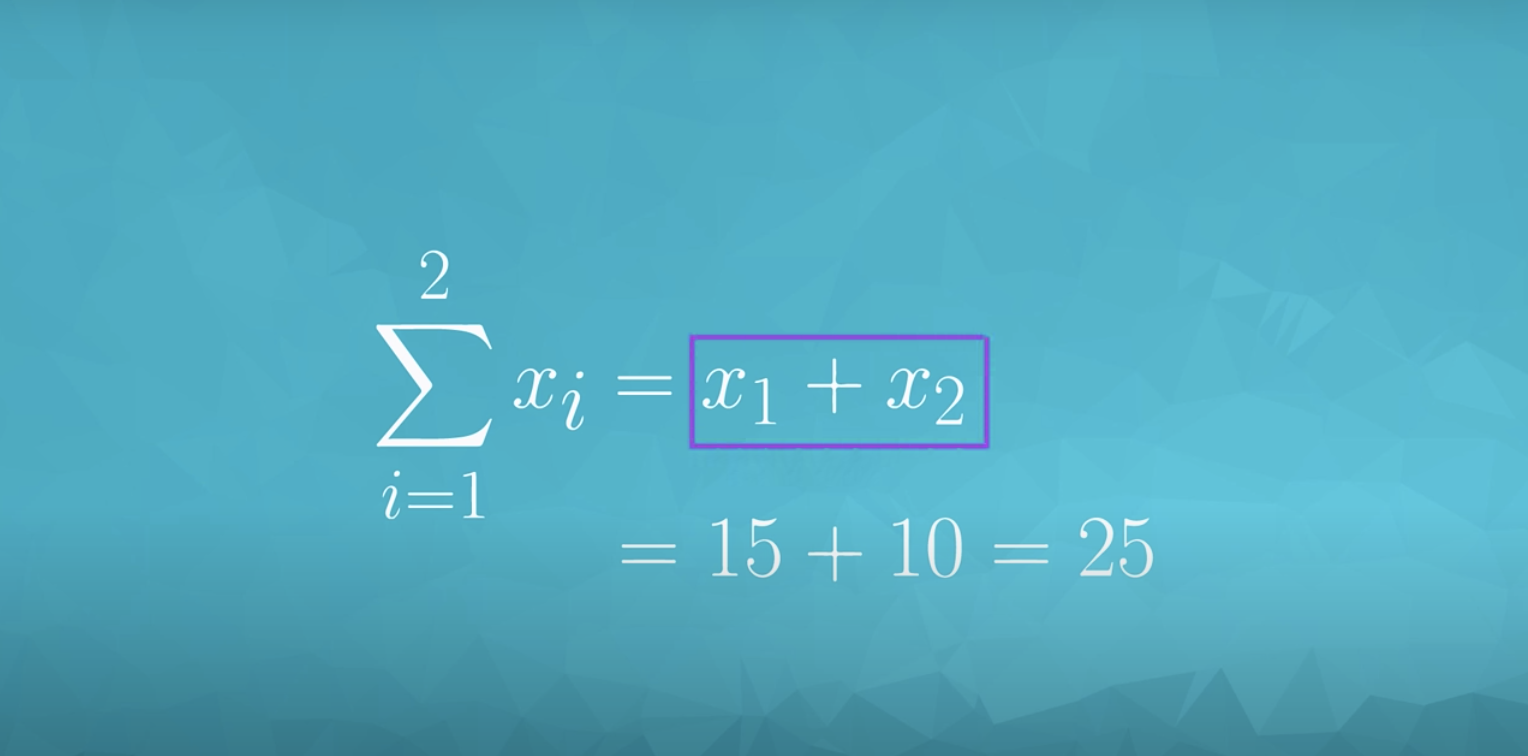
Notation for the Mean
Pay attention to 1:15
Final Steps for Calculating the Mean
To finalize our calculation of the mean, we introduce n as the total number of values in our dataset. We can use this notation both at the top of our summation, as well as for the value that we divide by when calculating the mean.
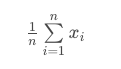
Instead of writing out all of the above, we commonly write x bar to represent the mean of a dataset. Although, similar to the first video, we could use any variable. Therefore, we might also write y bar, or any other letter.

We also could index using any other letter, not just ii. We could just as easily use jj, kk, or mm to index each of our data values. The quizzes on the next concept will help reinforce this idea.

Notation Recap
Notation
Notation is an essential tool for communicating mathematical ideas. We have introduced the fundamentals of notation in this lesson that will allow you to read, write, and communicate with others using your new skills!
Notation and Random Variables
As a quick recap, capital letters signify random variables. When we look at individual instances of a particular random variable, we identify these as lowercase letters with subscripts attach themselves to each specific observation.
For example, we might have X be the amount of time an individual spends on our website. Our first visitor arrives and spends 10 minutes on our website, and we would say \bold{x_1}x 1 is 10 minutes.
We might imagine the random variables as columns in our dataset, while a particular value would be notated with the lower case letters.

Notation for the Mean
We took our notation even farther by introducing the notation for summation ∑. Using this we were able to calculate the mean as:
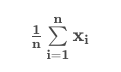
In the next section, you will see this notation used to assist in your understanding of calculating various measures of spread. Notation can take time to fully grasp. Understanding notation not only helps in conveying mathematical ideas, but also in writing computer programs - if you decide you want to learn that too! Soon you will analyze data using spreadsheets. When that happens, many of these operations will be hidden by the functions you will be using. But until we get to spreadsheets, it is important to understand how mathematical ideas are commonly communicated. This isn’t easy, but you can do it!
Lesson 2: Descriptive Statistics II
What are Measures of Spread
Measures of Spread
Measures of Spread are used to provide us an idea of how spread out our data are from one another. Common measures of spread include:
Throughout this lesson you will learn how to calculate these, as well as why we would use one measure of spread over another.
Histograms
Histograms
Histograms are super useful to understanding the different aspects of quantitative data. In the upcoming concepts, you will see histograms used all the time to help you understand the four aspects we outlined earlier regarding a quantitative variable:
- center
- spread
- shape
- outliers
Introduction to Five Number Summary
Calculating the 5 Number Summary
The five number summary consist of 5 values:
- Minimum: The smallest number in the dataset.
- Q1: The value such that 25% of the data fall below.
- Q2: The value such that 50% of the data fall below.
- Q3: The value such that 75% of the data fall below.
- Maximum: The largest value in the dataset.
In the above video we saw that calculating each of these values was essentially just finding the median of a bunch of different dataset. Because we are essentially calculating a bunch of medians, the calculation depends on whether we have an odd or even number of values.
Range
The range is then calculated as the difference between the maximum and the minimum.
IQR
The interquartile range is calculated as the difference between Q3 and Q1.
In the upcoming sections, you will practice this with Katie and on your own.
Introduction to Standard Deviation and Variance
Standard Deviation and Variance
Standard Deviation
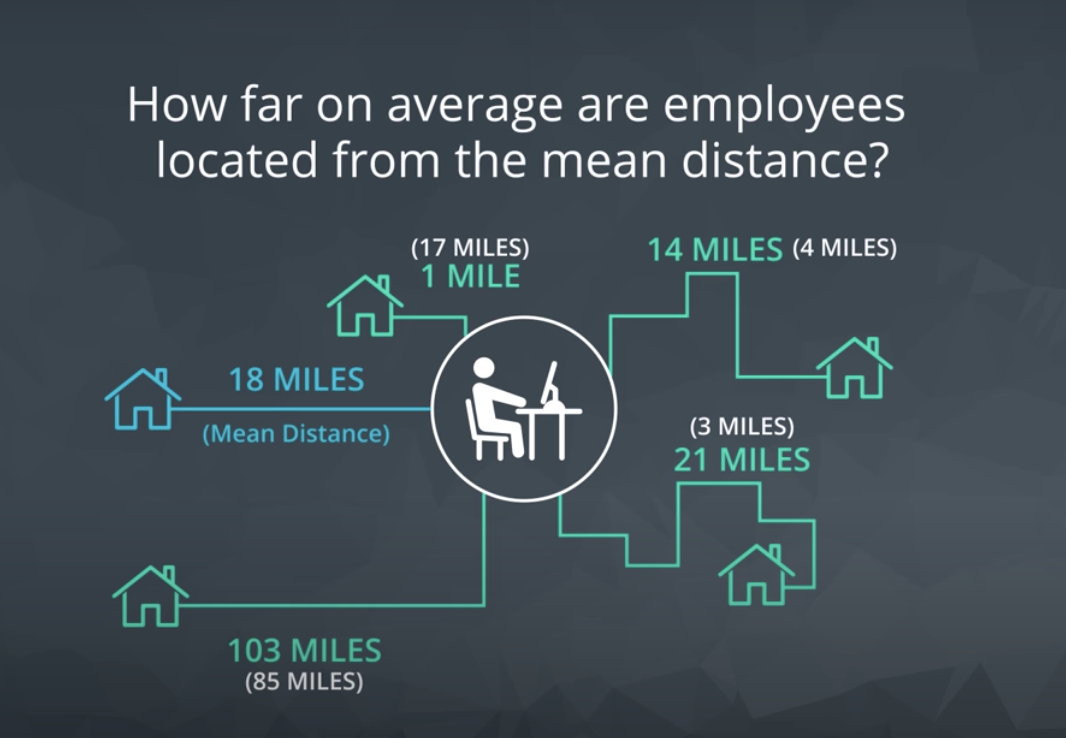
The standard deviation is one of the most common measures for talking about the spread of data. It is defined as the average distance of each observation from the mean.
In the above video we saw this as how far individuals were from the average distance from work (the example distances shown are examples from the full data set, the mean of just those 4 numbers is 38.5. The mean of 18 shown later in the video is the mean of the full data set which is not shown in the video). In the next video, you will see exactly how this is calculated.
Standard Deviation Calculation
- Find the Mean

- Look at the distance from each observation from the mean

- Then Average it

But zero is not a good measure of spread!
So we need to make all the values positive, the way we do this when calculating standard deviation is by squaring it

Average this to find the averaged squared distance from the mean

Variance
This is called the Variance – The average squared difference of each observation form the mean. However, this is the averaged of squared values, which we only did to get positive values in the first place.
The units of the variance are the square of the original units of your data.
To get the Standard Deviation: Get the square root of the ending value:

This is called the Standard Deviation – on average, how far each point in our dataset is from the mean.
Other Measures of Spread
5 Number Summary
In the previous sections, we have seen how to calculate the values associated with the five number summary (min, Q1, Q2, Q3, max), as well as the measures of spread associated with these values (range and IQR).
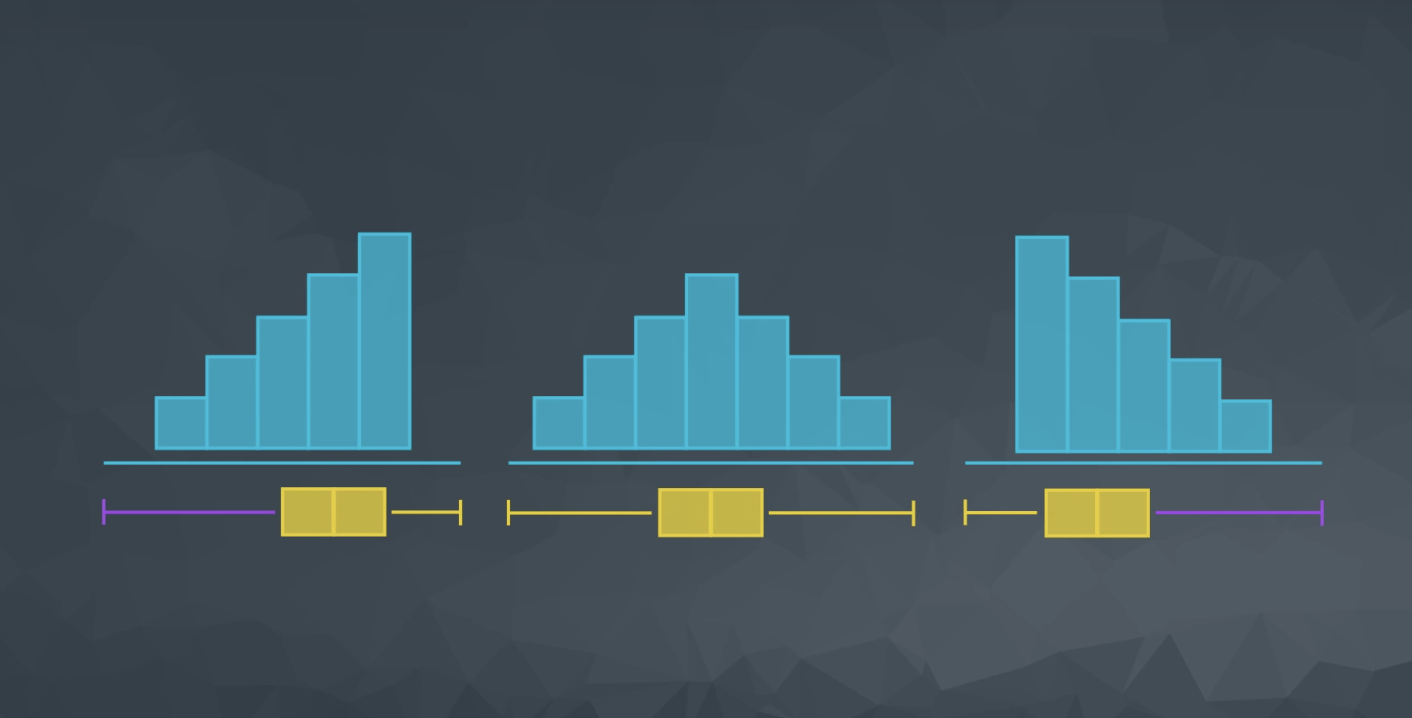
For datasets that are not symmetric, the five number summary and a corresponding box plot are a great way to get started with understanding the spread of your data. Although I still prefer a histogram in most cases, box plots can be easier to compare two or more groups. You will see this in the quizzes towards the end of this lesson.
Variance and Standard Deviation
Two additional measures of spread that are used all the time are the variance and standard deviation. At first glance, the variance and standard deviation can seem overwhelming. If you do not understand the expressions below, don’t panic! In this section, I just want to give you an overview of what the next sections will cover. We will walk through each of these parts thoroughly in the next few sections, but the big picture goal is to generally understand the following:
- How the mean, variance and standard deviation are calculated.
- Why the measures of variance and standard deviation make sense to capture the spread of our data.
- Fields where you might see these values used.
- Why we might use the standard deviation or variance as opposed to the values associated with the 5 number summary for a particular dataset.
Calculation
We calculate the variance in the following way:
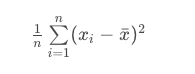
The variance is the average squared difference of each observation from the mean.
To calculate the variance of a set of 10 values in a spreadsheet application, with our 10 data points in column A, we would create a new column B by typing in something like =A1-AVERAGE(A$1:A$10) and copying this down for all 10 rows. This would find us the difference between each data point and the mean average of all the data. Then we create a new column C having the square of these differences, using the formula =B1^2 in cell C1, and copying that down for all rows. Then in the cell below this new column, cell C11, type in =SUM(C1:C10). This adds up all these values in column C. Finally in cell C12, we divide this sum by the number of data points we have, in this case ten: =C11/10. This cell C12 now contains the variance for our 10 data points.
Calculating Standard Deviation and Variance
More detailed guidance on using spreadsheets like this may be included in a future lesson in your program.
The standard deviation is the square root of the variance. Therefore, the formula for the standard deviation is the following:
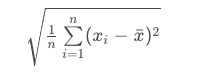
In the same spreadsheet as above, to find the standard deviation of our same set of 10 data values, we would use another cell like C13 to take the square root of our variance measure, by typing in =sqrt(C12).
The standard deviation is a measurement that has the same units as our original data, while the units of the variance are the square of the units in our original data. For example, if the units in our original data were dollars, then units of the standard deviation would also be dollars, while the units of the variance would be dollars squared.
Again, this section is designed as background knowledge for the following sections. If it doesn’t make sense on this first pass, do not worry. You will be guided in future sections in performing these calculations, and building your intuition, as you work through an example using the salary data. Then we will provide context about why these calculations are important, and where you might see them!
Why the Standard Deviation?
Important Final Points
Important Final Points
-
The variance is used to compare the spread of two different groups. A set of data with higher variance is more spread out than a dataset with lower variance. Be careful though, there might just be an outlier (or outliers) that is increasing the variance, when most of the data are actually very close.
-
When comparing the spread between two datasets, the units of each must be the same.
-
When data are related to money or the economy, higher variance (or standard deviation) is associated with higher risk.
-
The standard deviation is used more often in practice than the variance, because it shares the units of the original dataset.
Use in the World
The standard deviation is associated with risk in finance, assists in determining the significance of drugs in medical studies, and measures the error of our results for predicting anything from the amount of rainfall we can expect tomorrow to your predicted commute time tomorrow.
These applications are beyond the scope of this lesson as they pertain to specific fields, but know that understanding the spread of a particular set of data is extremely important to many areas. In this lesson you mastered the calculation of the most common measures of spread.
Little tidbits from the quizzes
-
Additionally, the range isn’t directly associated with the standard deviation, so we can’t make a claim that is always true like the final option.
-
Since the standard deviation is a measure of spread, a zero value suggests that all of our data points are the same value.
-
Besides the mean return of an investment, we should also consider the spread associated with the return. But just because the standard deviation associated with each investment is the same, this does not mean the max you could make for each investment is the same.
Real World Example from Quizzes
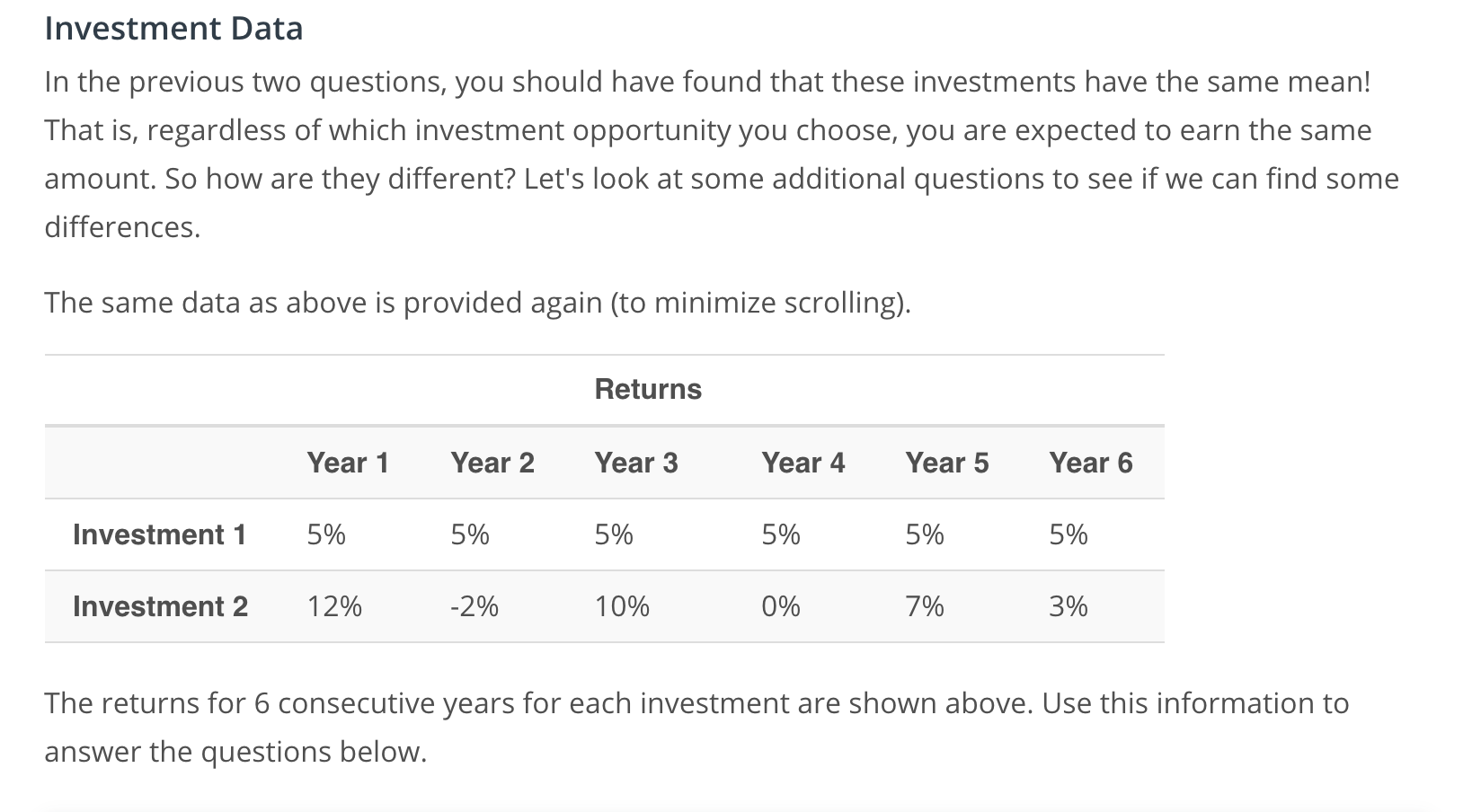

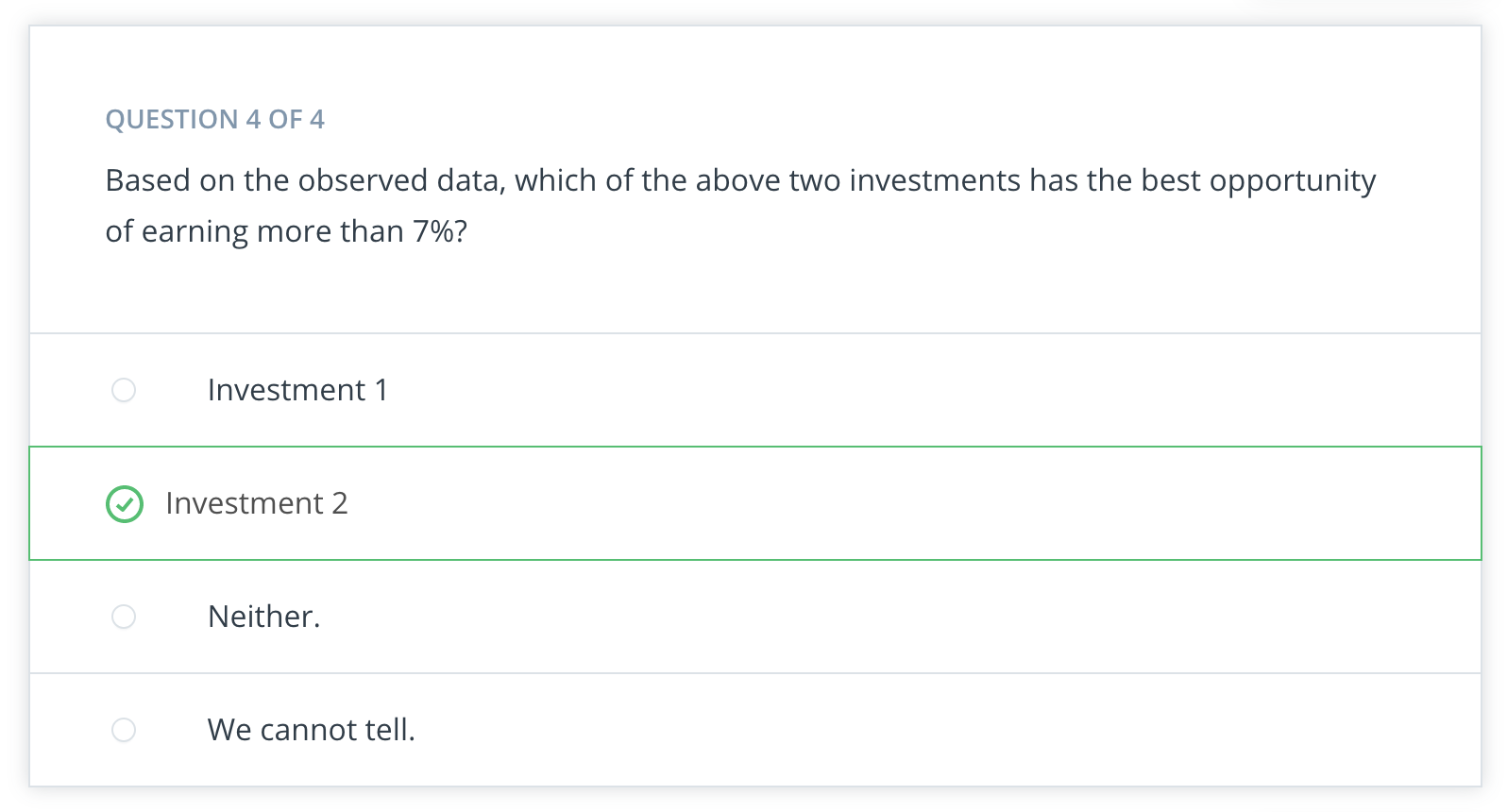
Useful insight
The above example is a simplified version of the real world, but does point out something useful that you may have heard before. Notice if you were not fully invested in either Investment 1 or fully invested in Investment 2, but instead you were diversified across both investment options, you could earn more than either investment individually. This is the benefit of diversifying your portfolio for long term gains. For short term gains, you might not need or want to diversify. You could get lucky and hit short term gains associated with the upswings (12%, 10%, or 7%) of Investment 2. However, you might also get unlucky, and hit a down term and earn nothing or even lose money on your investment using this same strategy.
Measures of Center and Spread Summary
Variable Types
We have covered a lot up to this point! We started with identifying data types as either categorical or quantitative. We then learned, we could identify quantitative variables as either continuous or discrete. We also found we could identify categorical variables as either ordinal or nominal.
Categorical Variables
When analyzing categorical variables, we commonly just look at the count or percent of a group that falls into each level of a category. For example, if we had two levels of a dog category: lab and not lab. We might say, 32% of the dogs were lab (percent), or we might say 32 of the 100 dogs I saw were labs (count).
However, the 4 aspects associated with describing quantitative variables are not used to describe categorical variables.
Quantitative Variables
Then we learned there are four main aspects used to describe quantitative variables:
- Measures of Center
- Measures of Spread
- Shape of the Distribution
- Outliers
We looked at calculating measures of Center
- Means
- Medians
- Modes
We also looked at calculating measures of Spread
- Range
- Interquartile Range
- Standard Deviation
- Variance
Calculating Variance

The reason for this is beyond the scope of what we have covered thus far, but you can find an explanation here.
You can commonly find answers to your questions with a quick Google search. Now is a great time to get started with this practice! This answer should make more sense at the completion of this lesson.
Standard Deviation vs. Variance
The standard deviation is the square root of the variance. In practice, you usually use the standard deviation rather than the variance. The reason for this is because the standard deviation shares the same units with our original data, while the variance has squared units.
What Next?
In the next sections, we will be looking at the last two aspects of quantitative variables: shape and outliers. What we know about measures of center and measures of spread will assist in your understanding of these final two aspects.
Shape
Histograms
We learned how to build a histogram in this video, as this is the most popular visual for quantitative data.
Shape
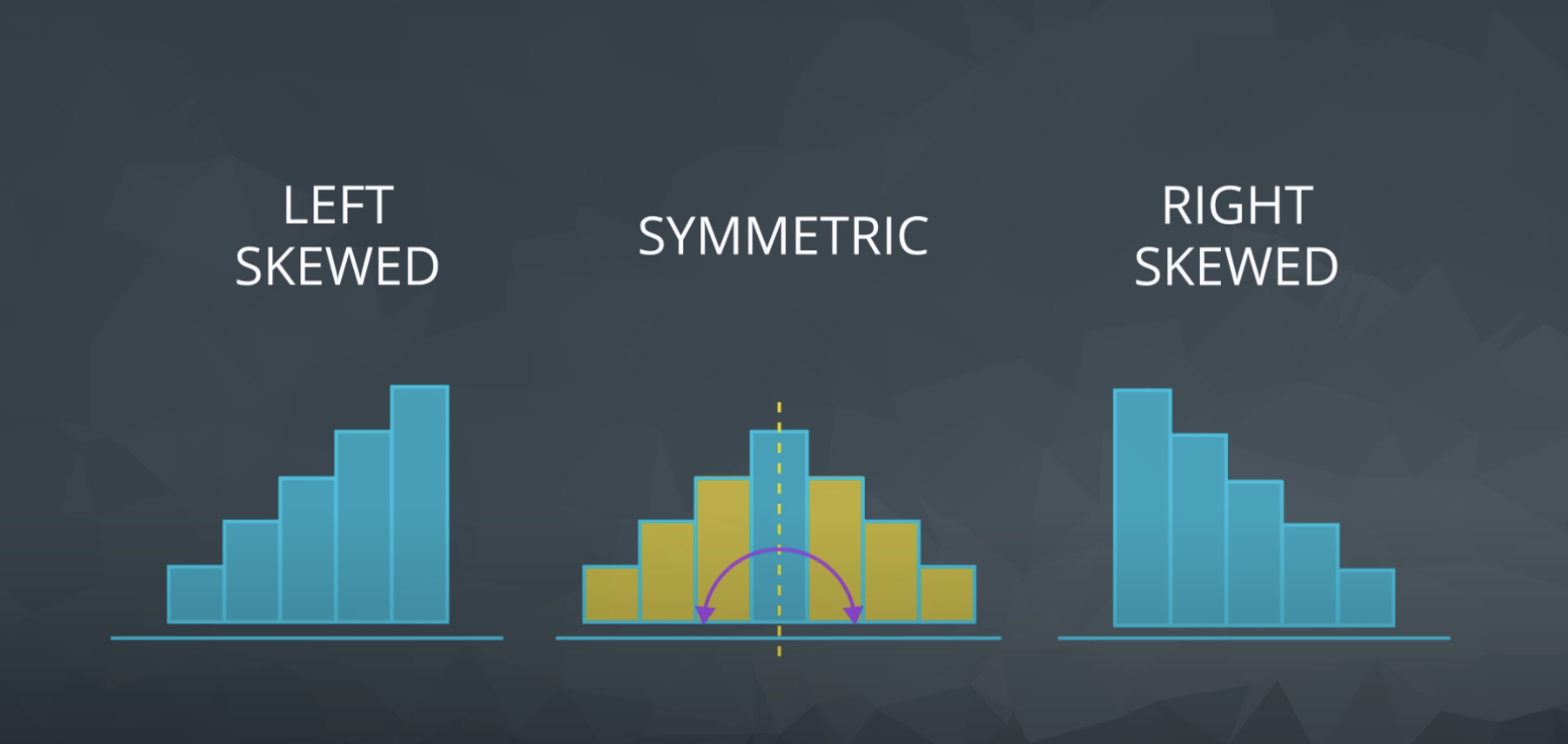
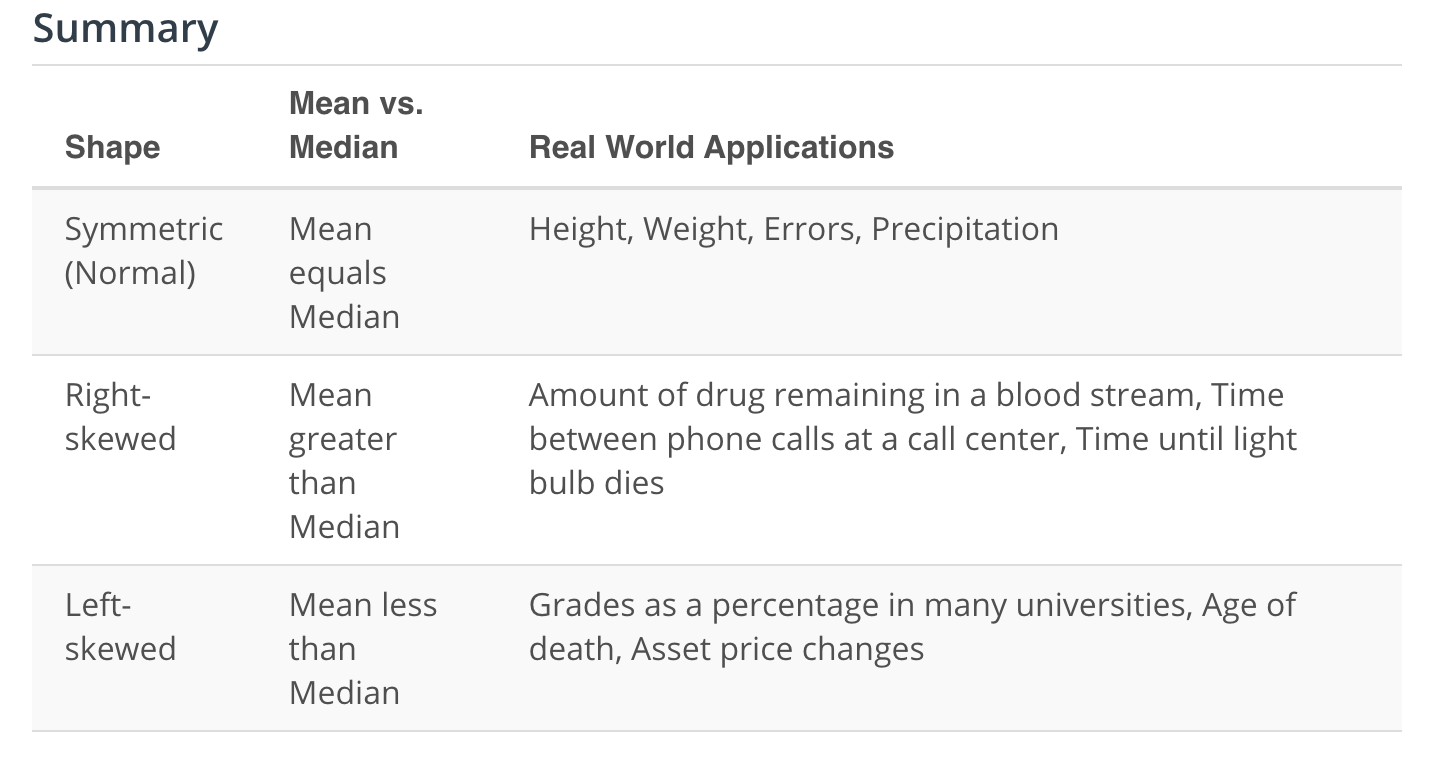
From a histogram we can quickly identify the shape of our data, which helps influence all of the measures we learned in the previous concepts. We learned that the distribution of our data is frequently associated with one of the three shapes:
-
Right-skewed
-
Left-skewed
-
Symmetric (frequently normally distributed)
The skew is the direction of the longer whisker.
The mode of a distribution is essentially the tallest bar in a histogram. There may be multiple modes depending on the number of peaks in our histogram.
The Shape of Data in Real World
References These are the references used to pull the applications of each shape.
Little tidbits from the quizzes
-
Remember right-skewed distributions have a tail towards larger values. How, do you think a few large values influences the mean?
-
Remember left-skewed distributions have a tail towards smaller values. How, do you think a few small values influences the mean?
-
The mean is pulled by the tail of the distribution.
Outliers
Outliers We learned that outliers are points that fall very far from the rest of our data points. This influences measures like the mean and standard deviation much more than measures associated with the five number summary.
Identifying Outliers There are a number of different techniques for identifying outliers. A full paper on this topic is provided here. In general, I usually just look at a picture and see if something looks suspicious!
Working with Outliers
Common Techniques When outliers are present we should consider the following points.
-
Noting they exist and the impact on summary statistics.
-
If typo - remove or fix
-
Understanding why they exist, and the impact on questions we are trying to answer about our data.
-
Reporting the 5 number summary values is often a better indication than measures like the mean and standard deviation when we have outliers.
-
Be careful in reporting. Know how to ask the right questions.
Outliers Advice
Below are my guidelines for working with any column (random variable) in your dataset.
-
Plot your data to identify if you have outliers.
-
Handle outliers accordingly via the methods above.
-
If no outliers and your data follow a normal distribution - use the mean and standard deviation to describe your dataset, and report that the data are normally distributed.
Side note
If you aren’t sure if your data are normally distributed, there are plots called normal quantile plots and statistical methods like the Kolmogorov-Smirnov test that are aimed to help you understand whether or not your data are normally distributed. Implementing this test is beyond the scope of this class, but can be used as a fun fact.
- If you have skewed data or outliers, use the five number summary to summarize your data and report the outliers.
Supporting Materials
Image Summary Quiz
Image Summary
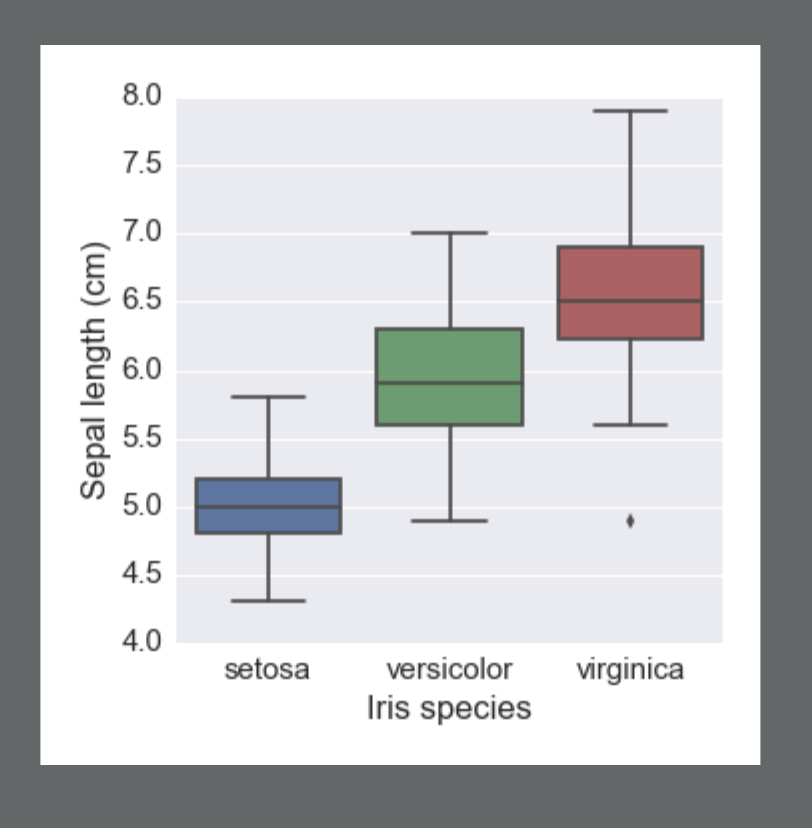
In the below image, we have three box-plots. Each box-plot is for a different Iris flower: setosa, versicolor, or virginica. On the y-axis, we are given the sepal length. Notice that virginica has an outlier towards the bottom of the plot. Therefore, the minimum is not given by the bottom line here; rather, it is provided by this point.





Example of Bi-modal distribution
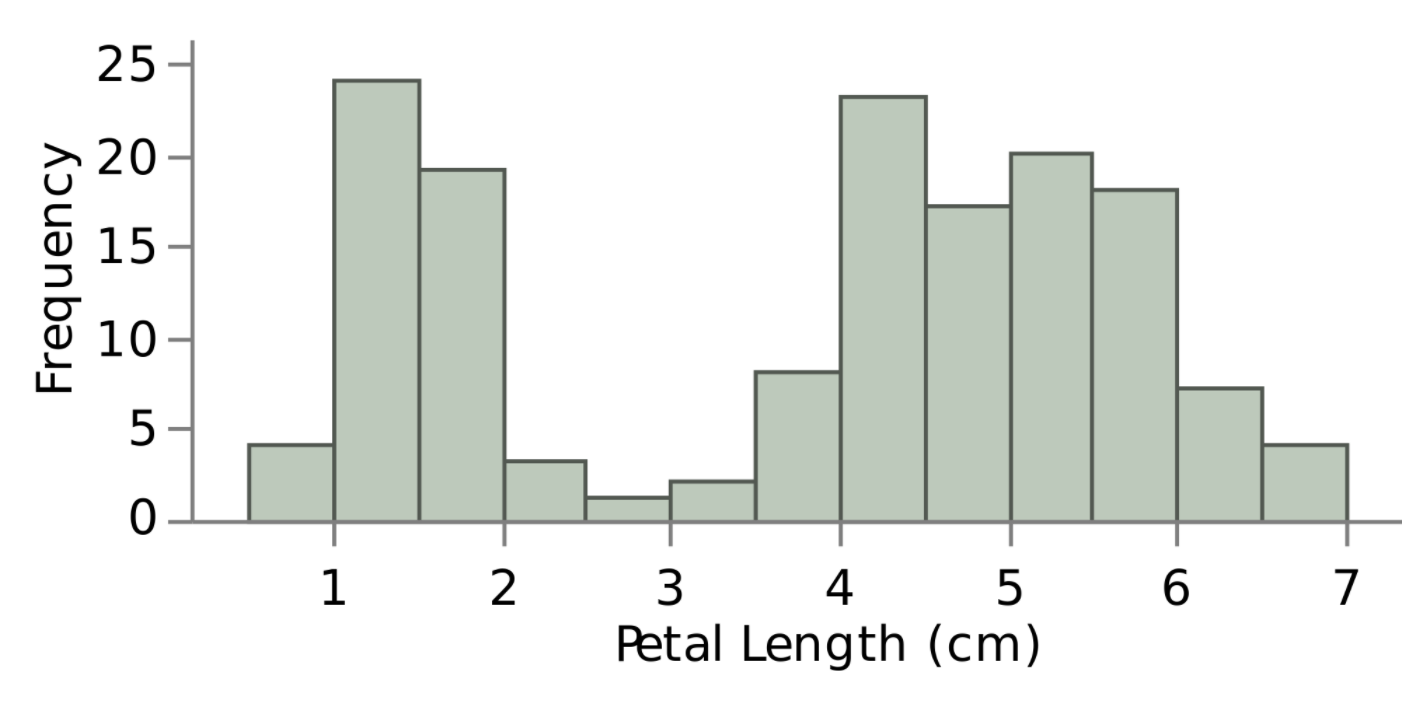
Notice it has two areas where there are peaks in our dataset.
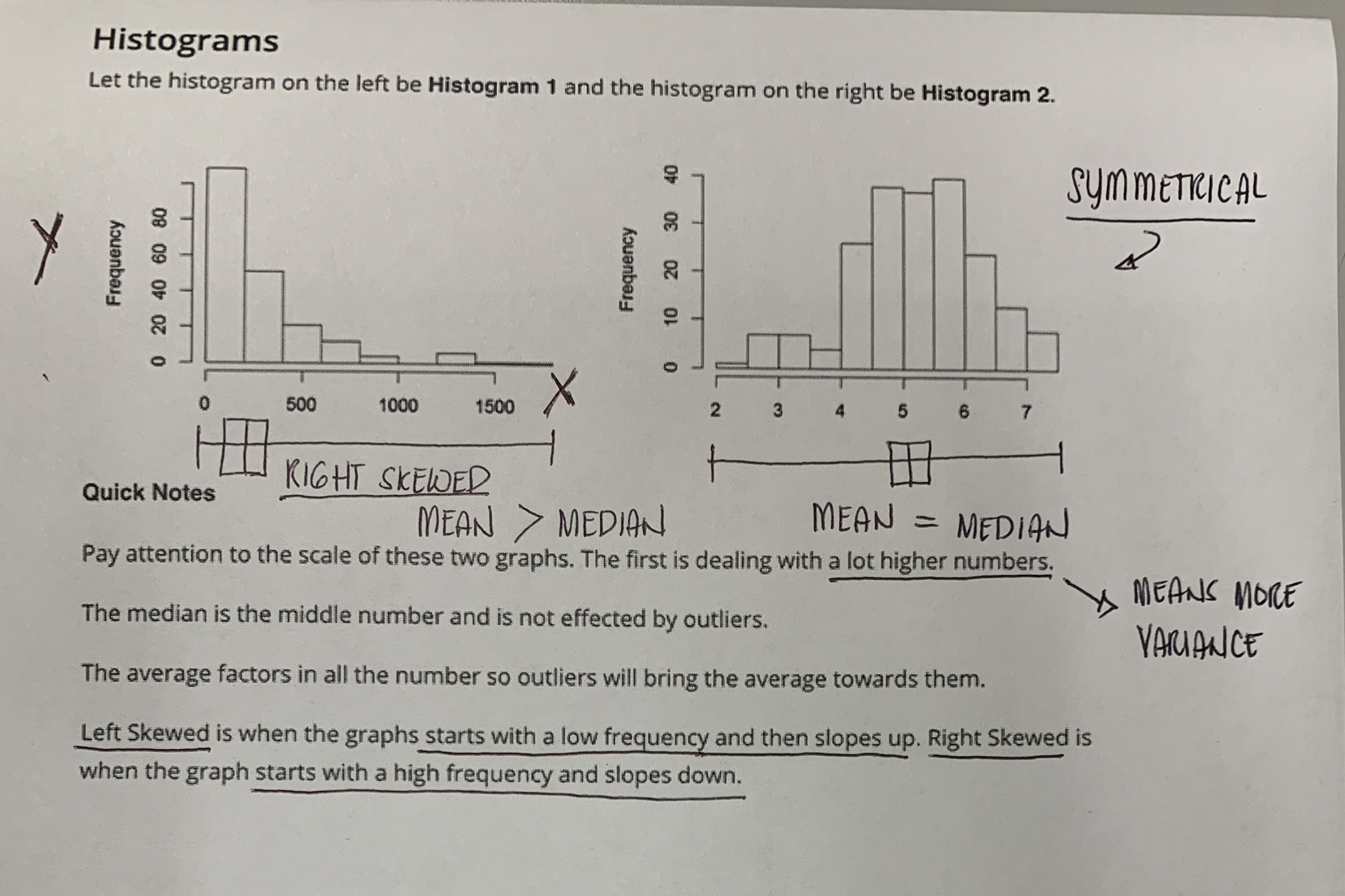

What Measures of Spread & Center Should We Use?
More On Center And Spread
When analyzing skewed data, it is common to report numeric summaries like the median and 5 number summary, as the mean and standard deviation may be misleading.
However, with symmetric data, the mean and standard deviation are commonly used, as we can understand what proportion of points might fall 1, 2, or 3 standard deviations away based on the empirical rule associated with normal distributions.
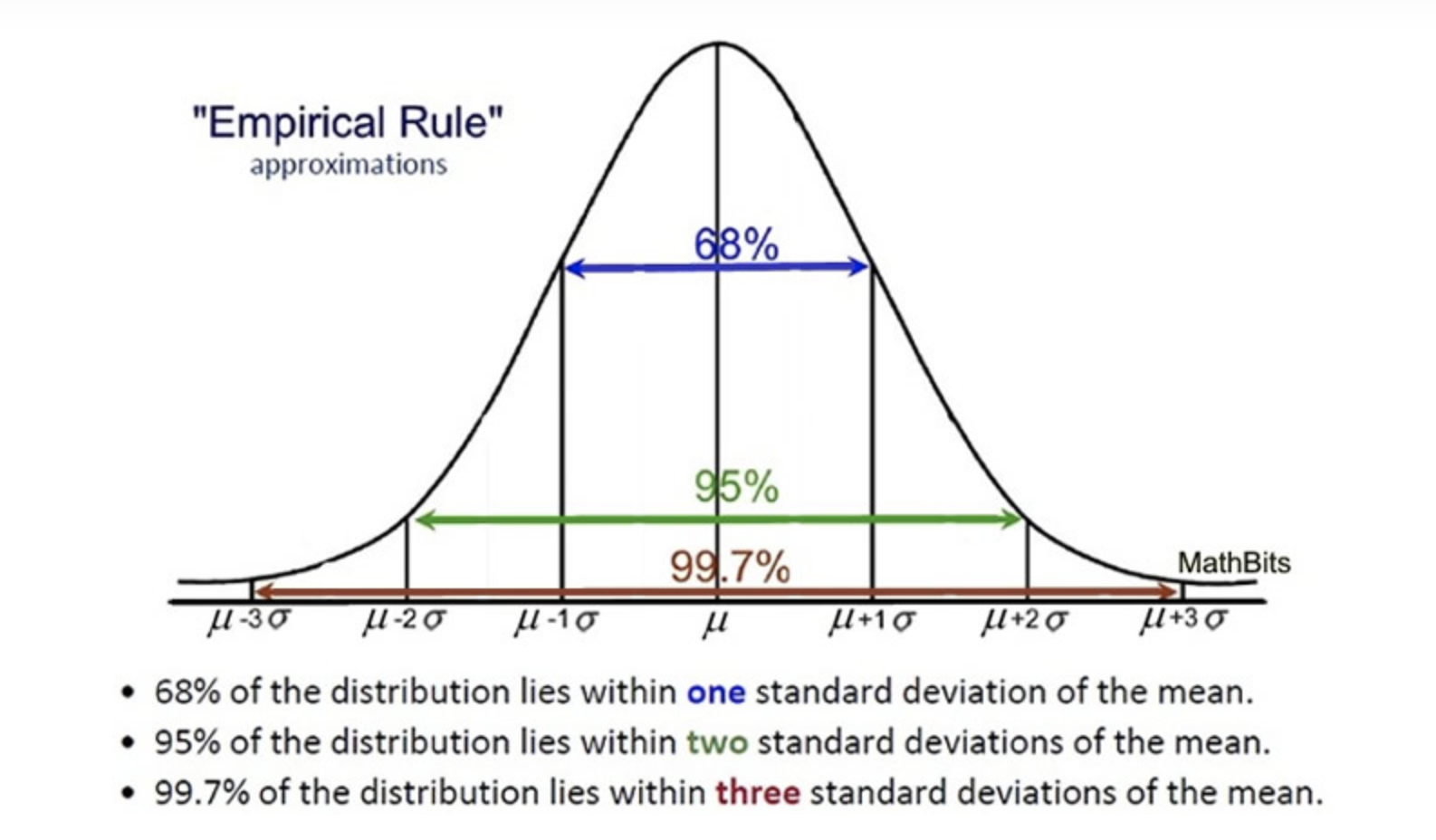
You can read more about this here.
Standard Deviation and Skewed Distributions
Standard Deviations can be calculated for any data set, whether it is normally distributed or skewed.
Also the standard deviation basically provides which of two sets of data are more spread out.
Recap
Variable Types
We have covered a lot up to this point! We started with identifying data types as either categorical or quantitative. We then learned, we could identify quantitative variables as either continuous or discrete. We also found we could identify categorical variables as either ordinal or nominal.
Categorical Variables
When analyzing categorical variables, we commonly just look at the count or percent of a group that falls into each level of a category. For example, if we had two levels of a dog category: lab and not lab. We might say, 32% of the dogs were lab (percent), or we might say 32 of the 100 dogs I saw were labs (count).
However, the 4 aspects associated with describing quantitative variables are not used to describe categorical variables.
Quantitative Variables
Then we learned there are four main aspects used to describe quantitative variables:
- Measures of Center
- Measures of Spread
- Shape of the Distribution
- Outliers
Measures of Center
We looked at calculating measures of Center
- Means
- Medians
- Modes
Measures of Spread
We also looked at calculating measures of Spread
- Range
- Interquartile Range
- Standard Deviation
- Variance
Shape
We learned that the distribution of our data is frequently associated with one of the three shapes:
-
Right-skewed
-
Left-skewed
-
Symmetric (frequently normally distributed)
Depending on the shape associated with our dataset, certain measures of center or spread may be better for summarizing our dataset.
When we have data that follows a normal distribution, we can completely understand our dataset using the mean and standard deviation.
However, if our dataset is skewed, the 5 number summary (and measures of center associated with it) might be better to summarize our dataset.
Outliers
We learned that outliers have a larger influence on measures like the mean than on measures like the median. We learned that we should work with outliers on a situation by situation basis. Common techniques include:
-
At least note they exist and the impact on summary statistics.
-
If typo - remove or fix
-
Understand why they exist, and the impact on questions we are trying to answer about our data.
-
Reporting the 5 number summary values is often a better indication than measures like the mean and standard deviation when we have outliers.
-
Be careful in reporting. Know how to ask the right questions.
Histograms and Box Plots
We also looked at histograms and box plots to visualize our quantitative data. Identifying outliers and the shape associated with the distribution of our data are easier when using a visual as opposed to using summary statistics.
What Next? Up to this point, we have only looked at Descriptive Statistics, because we are describing our collected data. In the final sections of this lesson, we will be looking at the difference between Descriptive Statistics and Inferential Statistics.
Descriptive vs. Inferential Statistics
In this section, we learned about how Inferential Statistics differs from Descriptive Statistics.
Descriptive Statistics
Descriptive statistics is about describing our collected data.
Inferential Statistics
Inferential Statistics is about using our collected data to draw conclusions to a larger population.
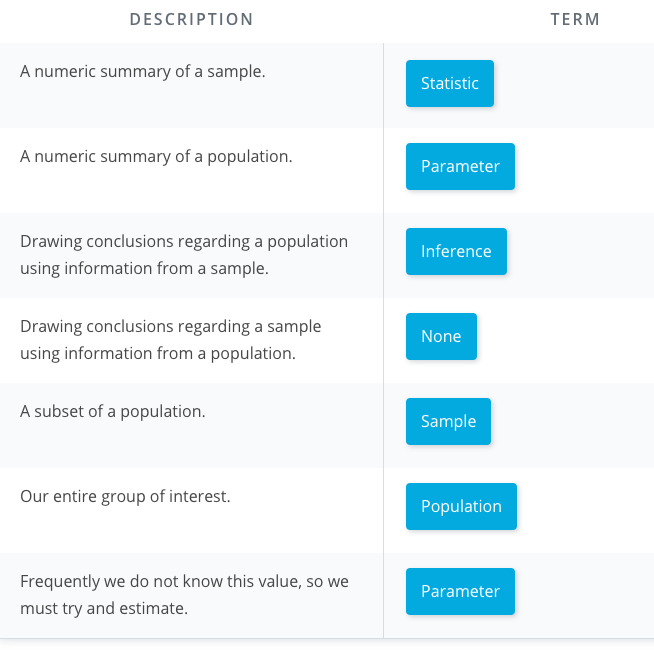
We looked at specific examples that allowed us to identify the
- Population - our entire group of interest.
- Parameter - numeric summary about a population
- Sample - subset of the population
- Statistic numeric summary about a sample
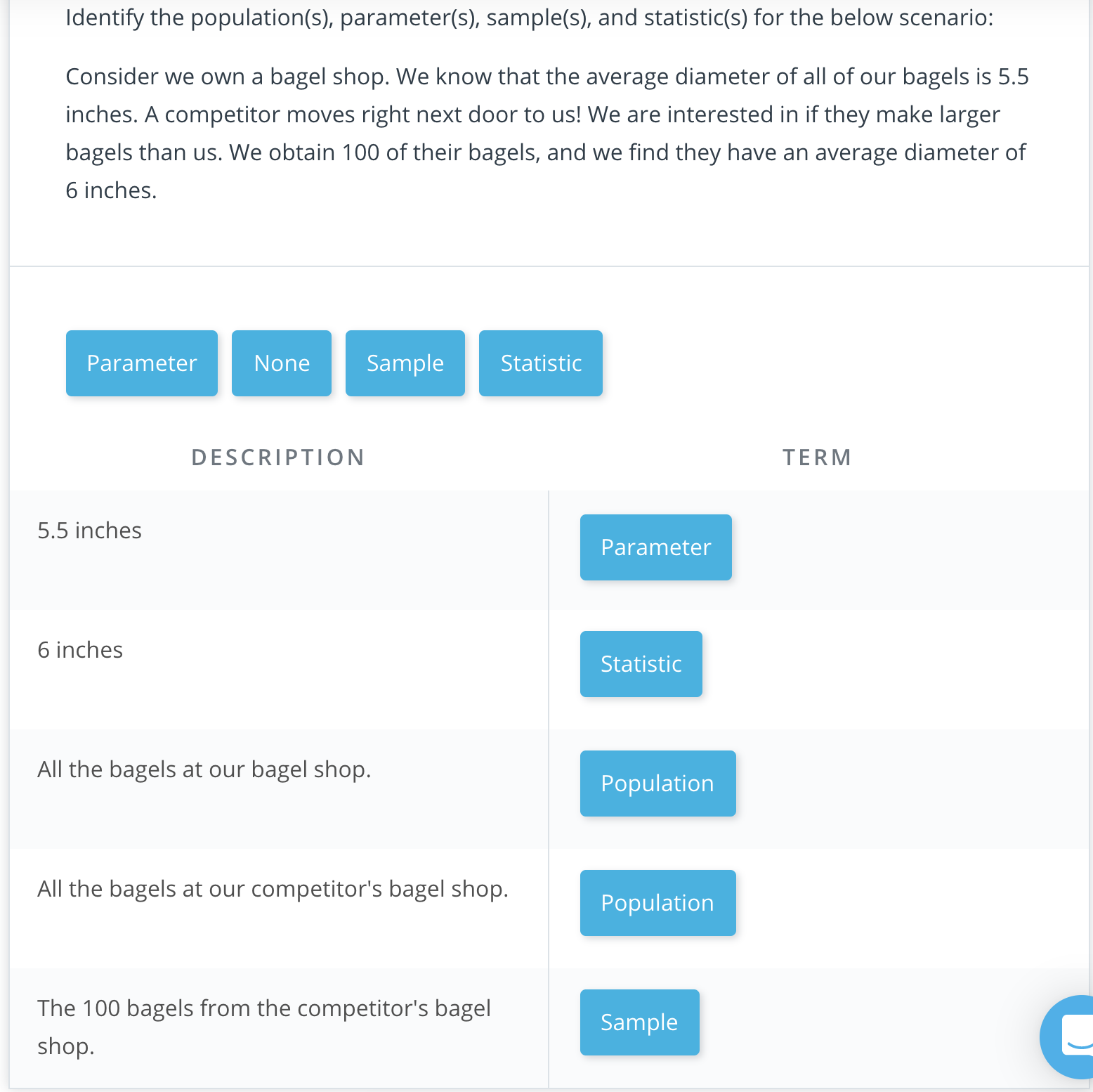
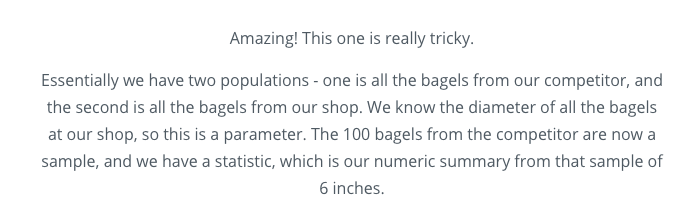

Recap
Descriptive vs. Inferential Statistics
In this section, we learned about how Inferential Statistics differs from Descriptive Statistics.
Descriptive Statistics
Descriptive statistics is about describing our collected data using the measures discussed throughout this lesson: measures of center, measures of spread, shape of our distribution, and outliers. We can also use plots of our data to gain a better understanding.
Inferential Statistics
Inferential Statistics is about using our collected data to draw conclusions to a larger population. Performing inferential statistics well requires that we take a sample that accurately represents our population of interest.
A common way to collect data is via a survey. However, surveys may be extremely biased depending on the types of questions that are asked, and the way the questions are asked. This is a topic you should think about when tackling the first project.
We looked at specific examples that allowed us to identify the
- Population - our entire group of interest.
- Parameter - numeric summary about a population
- Sample - subset of the population
- Statistic - numeric summary about a sample
Looking Ahead
Though we will not be diving deep into inferential statistics within this course, you are now aware of the difference between these two branches of statistics. If you have ever conducted a hypothesis test or built a confidence interval, you have performed inferential statistics. The way we perform inferential statistics is changing as technology evolves. Many career paths involving Machine Learning and Artificial Intelligence are aimed at using collected data to draw conclusions about entire populations at an individual level.